以下是自己结合postgreSQL文档手册总结整理的入门手札,如有不严谨,请到官方文档手册查看:http://www.postgres.cn/docs/10/index.html
数字类型
pgsql支持的数字类型有整数类型、用户指定精度类型、浮点型、和serial类型(自增)
数字类型图:
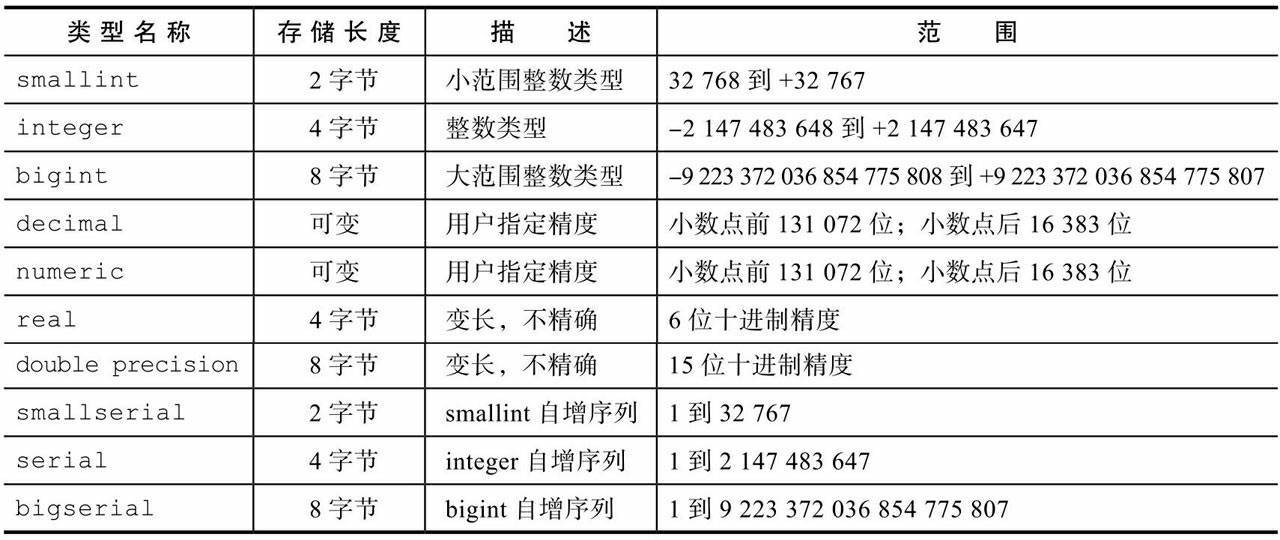
整数类型
smallint、integer、bigint都是整数类型,存储一定范围的整数,超出范围将会报错。
PS:
smallint字段定义时可以写成int2,integer比smallint大,所以是int4(最常用的整数类型),同理bigint可写成int8.
任意精度数字
类型decimal和numeric是等效的,可以存储非常多位的数字. 比如numeric的语法:
1.numberic(precision,scale) precision:指全部位数,必须为正整数-->(精度) scale:指小数部分的数字位数,可以为0或者整数-->(标度) 2.numberic(precision) 3.numberic
PS:
numberic类型性能比整数类型性能低,所以如果两种类型都能满足需求,建议使用整数类型。 最后:为了增强程序的移植性,最好同时指定numeric的精度和标度。
浮点类型
数据类型real和double precision是指浮点数据类型(不准确的、变精度的数字类型),real支持4字节,double precision是支持8字节。
序列号类型(官方文档–>序数类型)
smallserial、serial和bigserial是自增类型,但严格意义上它不是真正的类型,它们只是为了创建唯一标识符列而存在的方便符号(类似其它一些数据库中支持的AUTO_INCREMENT属性),如下代码:
CREATE TABLE test_serial (
id serial,
flag text
);
等价于以下语句:
CREATE SEQUENCE test_serial_seq;
CREATE TABLE test_serial (
id integer NOT NULL DEFAULT,
flag text
nextval('test_serial_seq')
);
ALTER SEQUENCE test_serial_seq OWNED BY test_serial.id;
简单的说,就是mysql自增(AUTO_INCREMENT).
PS:
类型名serial和serial4是等效的, 两个都创建integer列。
类型名bigserial和serial8也一样,只不过它们创建一个 bigint列。
类型名smallserial和serial2也以相同方式工作,只不过它们创建一个smallint列。
字符类型
字符串类型图,如下:

character varying(n)存储的是变长字符类型, 其中n是一个正整数,如果存储的字符串长度超过n会报错喔,但是如果存储字符串比n小的话,character varying(n)只会存储实际的字符串。
character(n)存储的是定长字符串,如果存储的字符串长度超过n会报错,比它小则会用空白填充…
说了那么多,还是用一个例子吧:
创建一个表
create table test_char(col1 varchar(4),col2 char(4));
---
插入数据
insert into test_char(col1,col2) values('a','a');
---
比较字符串长度
select char_length(col1),char_length(col2) from test_char;
----
char_length char_length1
1 1
----
比较字符串占用的字节数
select octet_length(col1),octet_length(col2) from test_char
----
octet_length octet_length1
1 4
S:
varchar(n)和char(n)的概念分别是character varying(n)和character(n)的别名。没有长度声明词的character等效于character(1)。如果不带长度说明词使用character varying,那么该类型接受任何长度的串。后者是一个PostgreSQL的扩展。
text字符类型,它可以存储任何长度的串。和没有什么字符长度的character varying(n)字符类型几乎没有差别。
PS:
这三种类型之间没有性能差别,只不过是在使用填充空白的类型的时候需要更多存储尺寸,以及在存储到一个有长度约束的列时需要少量额外CPU周期来检查长度。虽然在某些其它的数据库系统里,character(n)有一定的性能优势,但在PostgreSQL里没有。事实上,character(n)通常是这三种类型之中最慢的一个,因为它需要额外的存储开销。在大多数情况下,应该使用text或者character varying.(postgreSQL支持字符串存储的最长字串大概是 1 GB)
日期/时间类型
PostgreSQL 支持 SQL标准中所有的日期和时间类型。 具体如下:
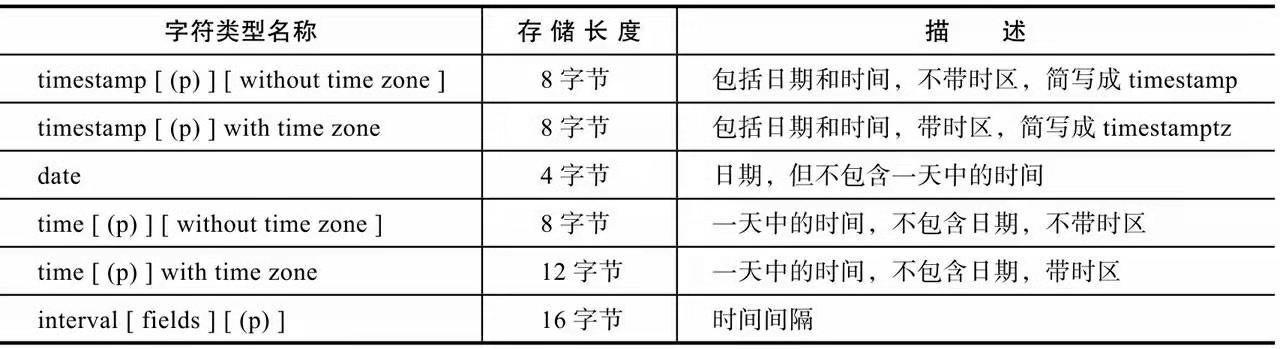
PS:
SQL要求只写timestamp等效于timestamp without time zone,并且PostgreSQL鼓励这种行为。timestamptz被接受为timestamp with time zone的一种简写,这是一种PostgreSQL的扩展
time、timestamp和interval接受一个可选的精度值 p,这个精度值声明在秒域中小数点之后保留的位数。缺省情况下,在精度上没有明确的边界,p允许的范围是从 0 到 6。
说了那么多,我们还是用实例说话吧… 首先先用系统自带的now()函数,now()函数显示是当前时间,并返回类型为:timestamp with time zone,如:
select now(); --- now 2019-10-20 00:23:25.288484+08
如果需要转到timestamp without time zone,并且不需要保留小数点,如
select now()::timestamp(0) without time zone; ---- now 2019-10-20 00:24:42
转换到date类型,如:
select now()::date; ---- now 2019-10-20
转到time without time zone,如:
select now()::time without time zone; ---- now 00:26:33.661496
最后就是interval类型,其实interval类型是有一个附加选项,它可以通过写下面之一的短语来限制存储的fields的集合:
year,month,day,hour,minute,second,yeartomonth,daytohour,daytominute,daytosecond,hourtominute,hourtosecond,minutetosecond
又来举个例子吧:
select now(),now()+interval '1 day' ---- now ?column? 2019-10-20 00:29:49.530872+08 2019-10-21 00:29:49.530872+08
剩下那么多附加选项,自己测吧…
布尔类型(boolean–>true/false)
“真(true)”状态的有效文字值是:
TRUE、’t’、’true’、’y’、’yes’、’on’、’1′
而对于“假”状态有效文字值是:
FALSE、’f’、’false’、’n’、’no’、’off’、’0′
知道我们的通病都不喜欢看文字,而看例子,如:
create table test_boolean(col1 boolean,col2 boolean);
----
insert into test_boolean(col1,col2) values('true','false');
insert into test_boolean(col1,col2) values('true','false');
insert into test_boolean(col1,col2) values('t','f');
insert into test_boolean(col1,col2) values('TRUE','FALSE');
insert into test_boolean(col1,col2) values('yes','no');
insert into test_boolean(col1,col2) values('y','n');
insert into test_boolean(col1,col2) values('1','0');
insert into test_boolean(col1,col2) values(null,null);
---------
select * from test_boolean
----
col1 col2
t f
t f
t f
t f
t f
t f
ps:一共有7条数据,其中布尔类型可以支持插入null字符...
网络地址类型
PostgreSQL提供用于存储 IPv4、IPv6 和 MAC 地址的数据类型,使用网络地址类型存储IP地址会优于字符类型,因为网络地址类型一方面会对数据合法性进行检查,另一方面也提供了网络地址类型相关的函数,方便我们使用吧..
网络地址数据类型,如下:

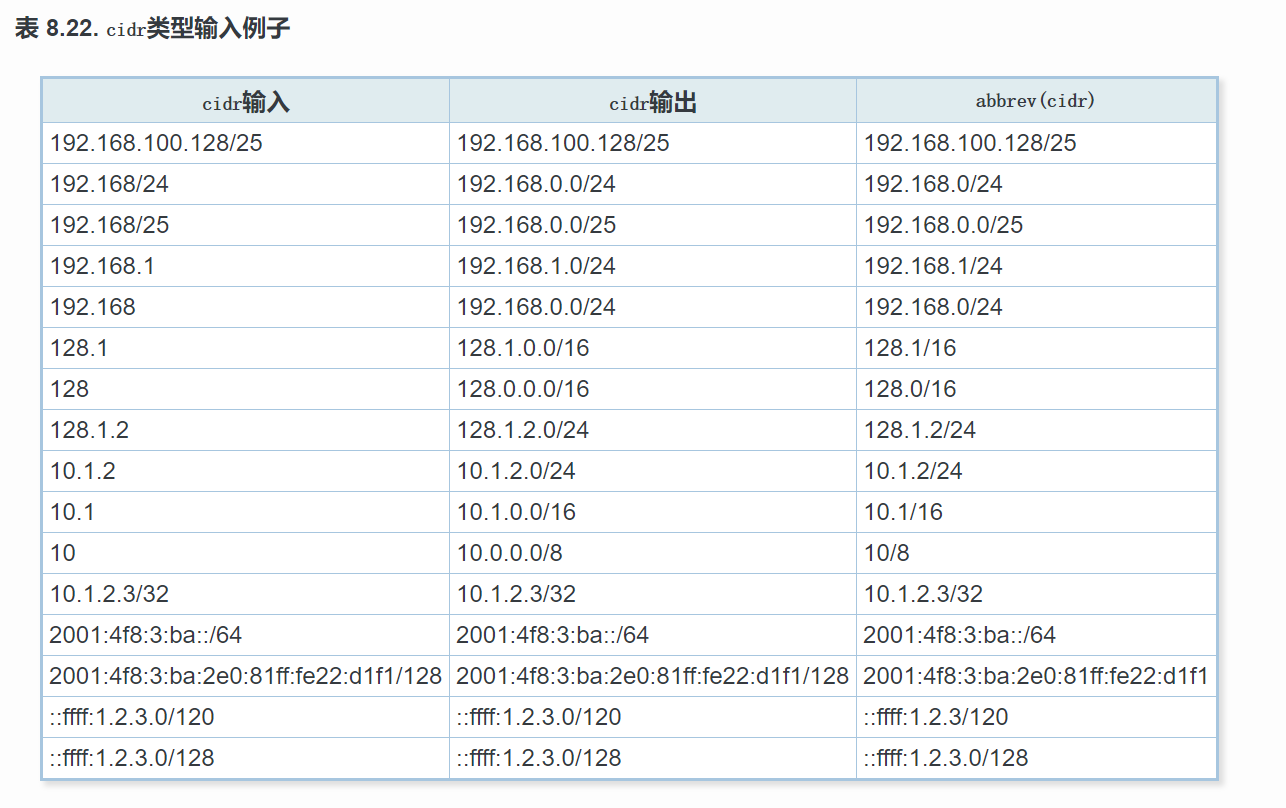
inet或者cidr类型存储的网络地址格式都为:address(地址)/y(网络掩码的位数)
address就是表示ipv4或者ipv6的网络地址 y表示网络掩码位数,如果y省略,则对于ipv4的网络掩码就为32,而ipv6则为128,因此该值表示只有一台主机。
如果y显示时,如果y部分指定一个单台主机,它将不会被显示出来。
之前说了inet或者cidr类型都会对数据合法性进行检查,如果数据不合法则会报错,如:
[SQL]select '192.168.1.1000'::inet [Err] ERROR: invalid input syntax for type inet: "192.168.1.1000" LINE 1: select '192.168.1.1000'::inet
inet和cidr网络类型也存在一定的差别哒。
1.cidr类型的输出默认带子网掩码信息,而inte不一定。如:
select '192.168.1.100'::cidr,'192.168.1.100'::inet --- cidr inet 192.168.1.100/32 192.168.1.100 --------- select '192.168.1.100/32'::cidr,'192.168.1.100/32'::inet --- cidr inet 192.168.1.100/32 192.168.1.100 -------- select '192.168.1.100'::cidr,'192.168.1.100/16'::inet --- cidr inet 192.168.1.100/32 192.168.1.100/16
2.cidr类型对ip地址和子网掩码合法性进行检查,而inte不会,如:
[SQL]select '192.168.1.100/8'::cidr
[Err] ERROR: invalid cidr value: "192.168.1.100/8"
LINE 1: select '192.168.1.100/8'::cidr
^
DETAIL: Value has bits set to right of mask.
--------------------
select '192.168.1.100/8'::inet
----
inet
192.168.1.100/8
从上面的例子看出,cidr比inet网络类型更加得严谨吧… 简单的说就是:
inet和cidr类型之间的本质区别是inet接受右边有非零位的网络掩码, 而cidr不接受。 例如,192.168.1.100/24对inet来说是有效的, 但是cidr来说是无效的。
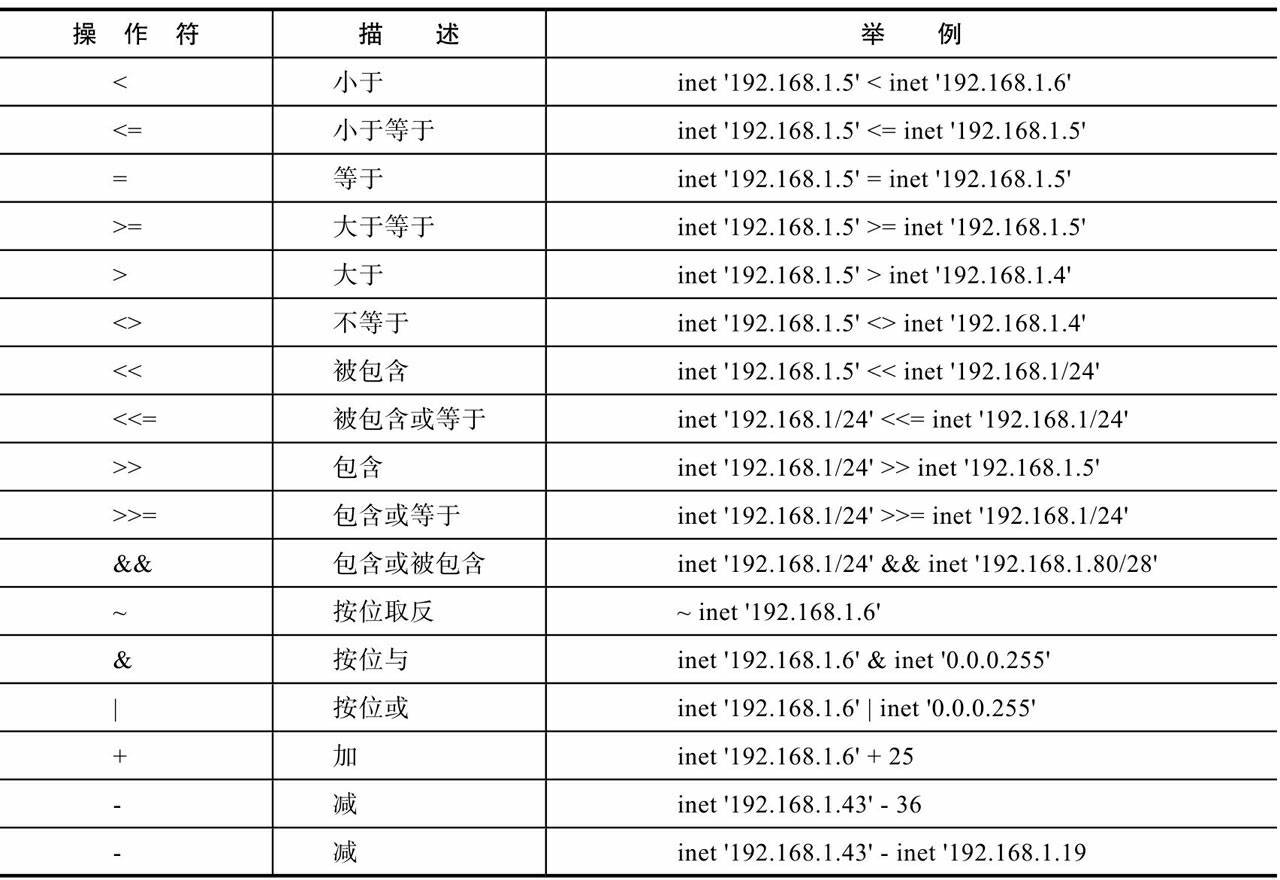
顺便记录一下网络操作符吧,因为oracle和mysql我自己也没有用到过网络类型的。
macaddr和macaddr8
macaddr和macaddr8是存储mac地址。对于mac的介绍更多可到:http://www.postgres.cn/docs/10/datatype-net-types.html
数组类型
postgreSQL支持一维数据or多维数组,常用的数据类型为数字类型的数组和字符串的数据,但也支持其他类型的吧?枚举类型、复合类型数组…怎么支持自己去全球最大的同性恋交友网站看官网手册..(github.com)
怎么用数组类型?噗,开玩笑我也不会… 那么我们就从怎么创建表开始吧..如:
create table test_array( id INTEGER, array_i INTEGER[], arrat_t TEXT[] );
从创表语句看,INTEGER[]就是Integer类型的一维数组了,同样,TEXT[]就是text类型的一维数据. 什么?那么二维数组呢???喵喵喵???不就是:
create table test_array_er( id INTEGER, array_i INTEGER[][], arrat_t TEXT[][] );
数组类型插入数据有两种方式,一种方式使用花括号的方式,即:{}–>:
'{val1 delim val2 delim ...}'
说白了,就是将数组元素值用花括号“{}”包围并用delim分隔符分开,delim分隔符常用基本上为逗号?如:
select '{1,2,3}'
----
?column?
{1,2,3}
往表test_array 插入一条数据:
insert into test_array(id,array_i,arrat_t)
values (1,'{1,2,3}','{"a","b","c"}');
往数组插入的第二张方式为使用array关键字,如:
select array[1,2,3]
----
array
{1,2,3}
往表test_array 插入一条数组:
insert into test_array(id,array_i,arrat_t) values (2,array[1,2,3],array['a','b','c']);
同理,如果插入多维数组表,如:
insert into test_array_er(id,array_i,arrat_t)
values (1,'{{1,2,3},{4,5,6}}','{{"a","b","c"},{"e","f","g"}}');
----
insert into test_array_er(id,array_i,arrat_t)
values (2,array[[1,2,3],[4,5,6]],array[['a','b','c'],['e','f','g']]);
查询数组元素
如果要查询数组所有元素值,只需要查询数组字段名称即可,如:
select array_i from test_array
数组元素的引用可以通过方括号[]方式,数据下表卸载方括号里面,范围基本上是1到n,n为数组长度,超出数据范围返回null,如:
select array_i[1],arrat_t[1] from test_array
数组元素追加、删除、更新
数组元素的追加使用array_append函数,如:
array_append(anyarray,anyelement)
使用array_append函数向数组末端追加一个元素,如:
select array_append(array[1,2,3],4)
----
array_append
{1,2,3,4}
也可以用array_prepend函数,如:
SELECT array_prepend(1, ARRAY[2,3]);
----
array_prepend
{1,2,3}
更可以用array_cat函数,如:
SELECT array_cat(ARRAY[1,2], ARRAY[3,4]);
----
array_cat
{1,2,3,4}
------------
SELECT array_cat(ARRAY[[1,2],[3,4]], ARRAY[5,6]);
array_cat
---------------------
{{1,2},{3,4},{5,6}}
array_prepend、array_append或array_cat这三个函数区别就是前两个函数仅支持一维数组,但array_cat支持多维数组。
数据元素追加到数组也可以使用||,如:
select array[1,2,3]||4
----
?column?
{1,2,3,4}
数组元素的删除是使用array_remove函数,如:
array_remove(anyarray,anyelement)
使用array_remove函数将移除数组中等于给定值的所有数组元素,如:
select array[1,2,2,3],array_remove(array[1,2,2,3],2)
----
array array_remove
{1,2,2,3} {1,3}
修改数组
1.一个数组值可以被整个替换:
花括号的语法方式:
update test_array set array_i='{2,3,4}' where id =1
----
使用ARRAY表达式语法:
update test_array set array_i=array[1,3,4] where id =1
2.可以在一个元素上被更新,如:
update test_array set array_i[3] = 5 where id =1
或者是二维数组的切片更新,如:
update test_array_er set array_i[1:2] = array[[7,8,9],[8,9,10]] where id =1
数组元素丰富的操作符:
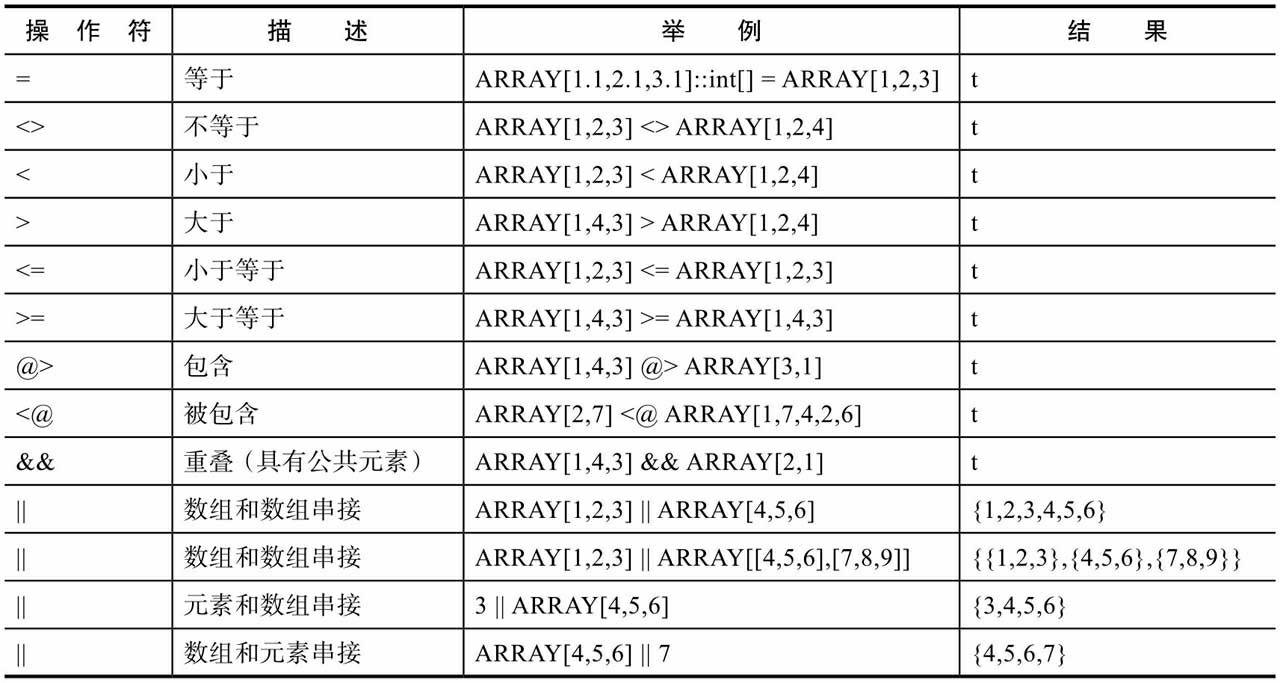
想要更深入了解数组类型,可到:http://www.postgres.cn/docs/10/arrays.html
json/jsonb类型
json类型
开始我们先用一个简单的json例子开启json类型的使用吧~
select '{"a":1,"b":2}'::json
----
json
{"a":1,"b":2}
这就是强转的一个小例子,我们还是创一个表吧,如:
create table test_json(
id serial primary key,
name json
);
insert into test_json(name) values('{"col1":1,"col2":"glj","col3":"male"}');
insert into test_json(name) values('{"col1":2,"col2":"hhm","col3":"famale"}');
select * from test_json;
-----
id name
1 {"col1":1,"col2":"glj","col3":"male"}
2 {"col1":2,"col2":"hhm","col3":"famale"}
查询json数据
通过‘->’操作符可以查询json数据的键值,如:
select name->'col2' from test_json ---- ?column? "glj" "hhm"
如果想以文本格式返回json字段的键值可以使用 ‘->>’操作符,如:
select name->>'col2' from test_json ---- ?column? glj hhm
jsonb键/值得追加、删除、更新
jsonb键/值追加可以通过||操作符,例如增加sex的键值,如:
select '{"name":"glj","age":23}'::jsonb || '{"sex":"male"}'::jsonb
----
?column?
{"age": 23, "sex": "male", "name": "glj"}
jsonb键/值删除有两种办法,一是通过操作符-删除,另一种是通过操作符 #- 删除指定的键/值, 首先先通过操作符- 删除键/值,如:
select '{"name":"glj","age":23,"sex":"male"}'::jsonb - 'sex'
----
?column?
{"age": 23, "name": "glj"}
再通过操作符 #- 删除键/值,但这种方式通常用于嵌套json的数据删除的,如:
select '{"name":"glj","contact":{"phone":"123456779","blogAddrUrl":"https://199604.com"}}'::jsonb #- '{contact,phone}'
------
?column?
{"name": "glj", "contact": {"blogAddrUrl": "https://199604.com"}}
方式二:删除contact中位置1的键/值,如:
select '{"name":"glj","contact":["0","1","2","3"]}'::jsonb #- '{contact,1}'
-----
?column?
{"name": "glj", "contact": ["0", "2", "3"]}
jsonb键/值更新也有两种办法,一种是操作符 ||的方式,如:
select '{"name":"glj","age":22}'::jsonb || '{"age":23}'
----
?column?
{"age": 24, "name": "glj"}
这种方式其实就是之前的笔记,jsonb的特点后续会说,就是jsonb会删除重复的键,仅仅保留最后一个。
第二种方式是通过jsonb_set函数,语法:
jsonb_set(target jsonb, path text[], new_value jsonb[, create_missing boolean])
target 指的是jsonb源数据,path 指的是路径 new_value指的是更新后的键值,create_missing当为true是,表示键不存在时,则添加,反之,不存在就不添加,如:
select jsonb_set('{"name":"glj","age":22}'::jsonb,'{age}','"23"'::jsonb,false)
----
jsonb_set
{"age": "23", "name": "glj"}
json和jsonb的对比差异
JSON 数据类型:json 和 jsonb,其实他们基本上一样哒,主要的实际区别之一是效率。因为json存储格式为文本,而jsonb存储格式为二进制,由于存储格式的不同使得两者数据类型的处理效率就不太一样了吧~json类型以文本存储并且存储的内容和输入的内容是一样的,当要检索json数据的时候,就需要重新解析,而jsonb不需要,因为它是二进制形式存储,已经解析好了数据,所以检索jsonb的数据时,不要重新解析即可查找,因此json写入比jsonb快,而检索时候就相反了。
说了那么多,我们用一个简单的例子看看吧,例如就是jsonb的输出键顺畅就和输入时候不一样,如:
select '{"name":"glj","age":23,"sex":"male"}'::jsonb,'{"name":"glj","age":23,"sex":"male"}'::json
------
jsonb json
{"age": 23, "sex": "male", "name": "glj"} {"name":"glj","age":23,"sex":"male"}
从上面看出来,json输入和输出顺序是一致的。 还有,就是jsonb类型会去掉输入数据中的键值空格,而json则不会,如:
select '{"name":"glj", "age":23,"sex":"male"}'::jsonb,
'{"name":"glj", "age":23,"sex":"male"}'::json
---------
jsonb json
{"age": 23, "sex": "male", "name": "glj"} {"name":"glj", "age":23,"sex":"male"}
最最最后,就是jsonb会删除重复的键,仅仅保留最后一个,如:
select '{"name":"glj","age":23,"sex":"male","name":"hhm"}'::jsonb,
'{"name":"glj","age":23,"sex":"male","name":"hhm"}'::json
-----
jsonb json
{"age": 23, "sex": "male", "name": "hhm"} {"name":"glj","age":23,"sex":"male","name":"hhm"}
看看吧,上面的name重复了,但是jsonb它是保留了最后一个name键的值,而json鸡巴没有这个校验的规则,它是你输入啥它就给你输出啥..所以建议尽量使用jsonb,而除非是那种鸡巴特殊需求除外,比如就是对json的键值有顺序要求的..(这句话说得好没有底气,因为我tm也是小白..)
jsonb和json操作符
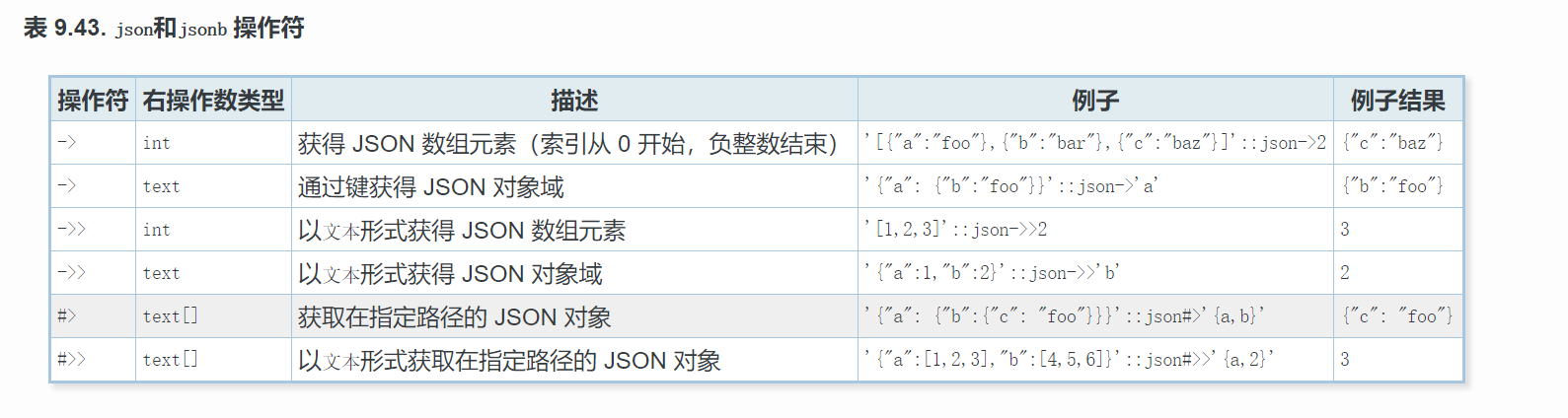
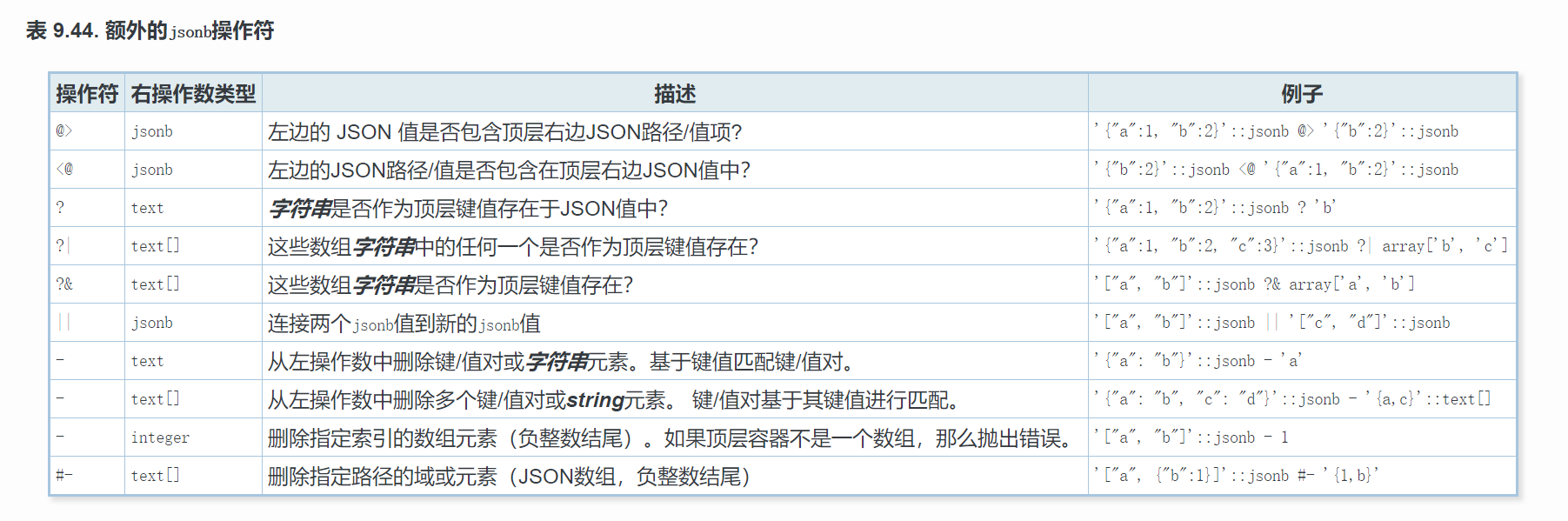
想要更深入了解json/jsonb类型,可到:http://www.postgres.cn/docs/10/datatype-json.html
码字挺辛苦哒~要不打个赏吧

大神牛逼!
喵喵喵???
非技术的路过。
您好,我来自V2ex,希望能跟您交换友情链接。
我的博客也基本上是技术类文章,全部都是原创内容。
希望得到回复,我的博客地址是:https://www.fi-ads.com/
已经添加您的链接到我的友情链接页面。
非常感谢!
不好意思哈~暂时不做,准备关站了
别关啊!毕竟很多年了!