本文最后更新于 1730 天前,其中的信息可能已经有所发展或是发生改变。
因为最近自己练手一个项目,需要用到全国省份市区数据,但是呢网上很多都不全或者需要收费才行。
于是就找到了民政局的网站,民政局的全国省份市区数据会定期更新,如果这个都不全那么还有那全对不对,所以就爬取民政局省市区数据,用于地市下拉框三级联动~确保数据的完整性.
url:http://www.mca.gov.cn/article/sj/xzqh/1980/
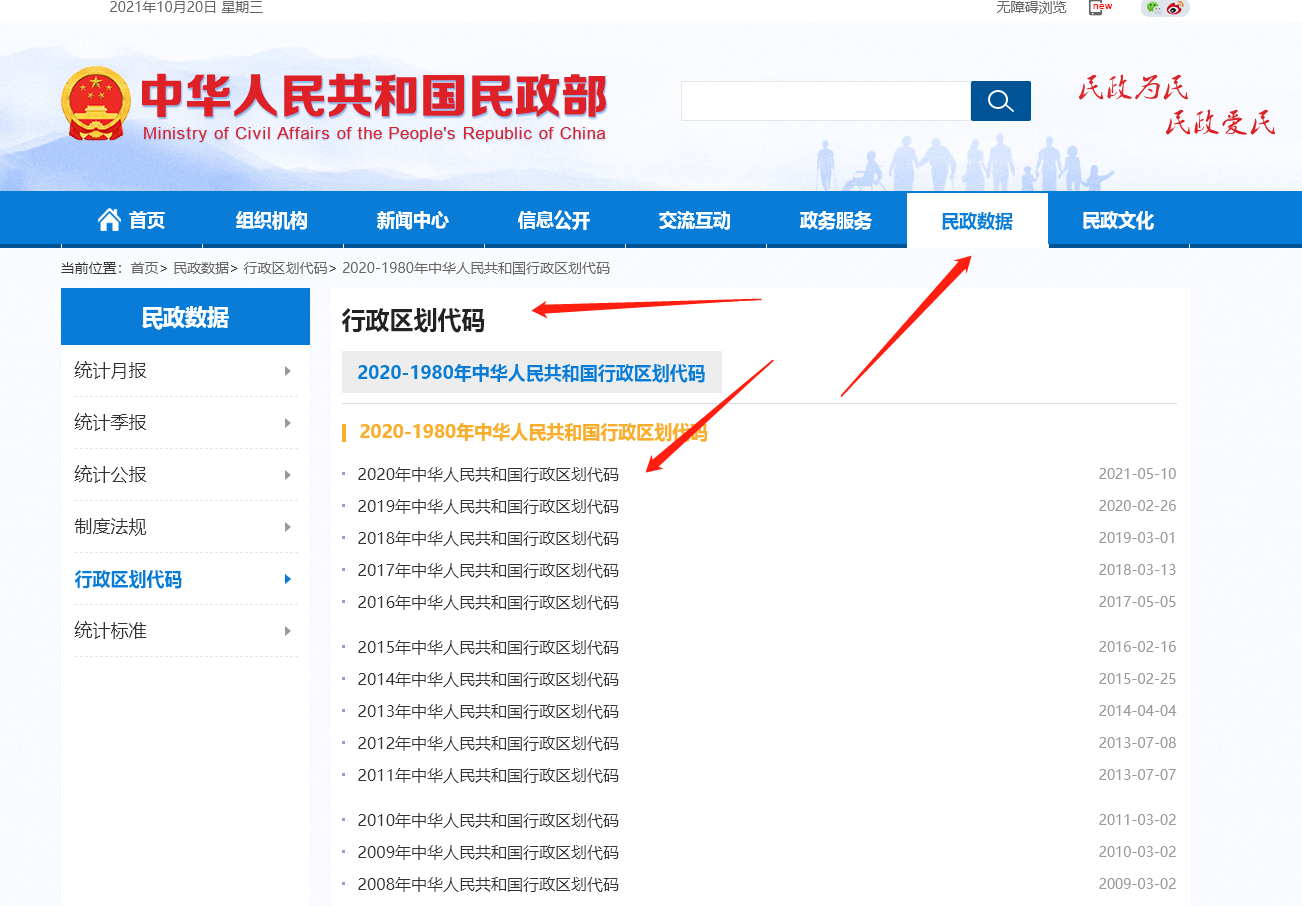

爬取地址如下:
http://www.mca.gov.cn/article/sj/xzqh/2020/20201201.html
开始
由于爬取原理很简单,就是解析HTML元素,然后获取到相应的属性值保存下来就好了。
本次是使用Java进行开发,所以选用Jsoup来完成这个工作。
源码具体放在这里:https://gitee.com/guoliangjun17/java-spider-data/tree/master/area
进入爬取地址进行Html分析
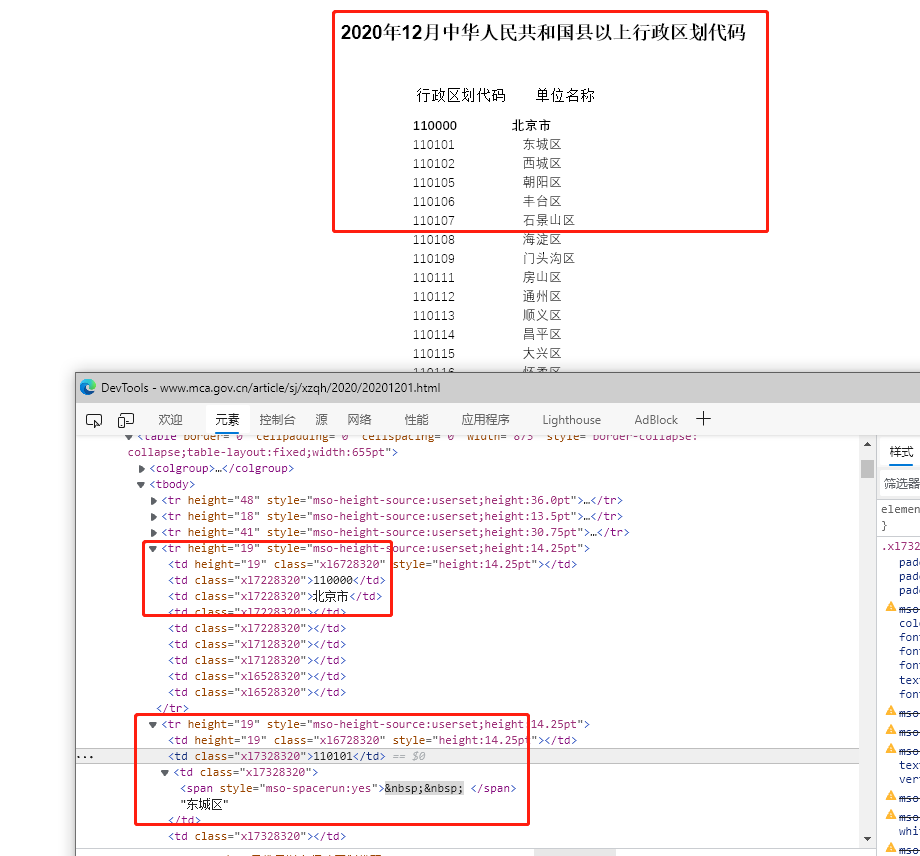
通过进行html分析,发现每一行数据都是存储在一个<tr>标签下。我们需要的是行政区域代码 和单位(地市)名称存储在第二和第三个<td>内 。与此同时还要很多空白<td>标签,在编写代码是需要将其过滤掉。具体逻辑如下:
Area实体类
@Data
@Builder
public class Area {
/**
* 父code
*/
private Integer parentCode;
/**
* 地市code
*/
private Integer cityCode;
/**
* 地市名称
*/
private String cityName;
}
AreaService服务类
@Service
public class AreaService {
/**
* 爬取目标url
*/
final String TARGET_URL = "http://www.mca.gov.cn/article/sj/xzqh/2020/20201201.html";
/**
* 使用非 stream的方式
* @throws IOException
*/
public void parseOne() throws IOException {
Document document = Jsoup.connect(TARGET_URL).timeout(100000).get();
Elements elements_tr = document.select("tr");
List<Area> list = new ArrayList<>();
for (int i=3;i<elements_tr.size();i++){
Element tr = elements_tr.get(i);
Elements elements_td = tr.select("td");
if (elements_td.size()>3) {
String cityCode = elements_td.get(1).text();
String cityName = elements_td.get(2).text();
if (StrUtil.isNotBlank(cityCode)&&StrUtil.isNotBlank(cityName)) {
Area area = Area.builder()
.parentCode(Integer.parseInt(checkParent(cityCode)))
.cityCode(Integer.parseInt(cityCode))
.cityName(cityName)
.build();
list.add(area);
}
}
}
list.forEach(System.out::println);
}
/**
* 使用stream的方式
* @throws IOException
*/
public void parseTwo() throws IOException {
List<Area> lists = Jsoup.connect(TARGET_URL).timeout(100000).get()
.select("tr")
.stream()
.map(
tr -> tr.select("td")
.stream()
.filter(td -> StrUtil.isNotBlank(td.text())).collect(Collectors.toList())
).filter(list -> list.size() == 2)
.skip(1)
.map(
e -> {
String cityCode = e.get(0).text();
String cityName = e.get(1).text();
Area area = Area.builder()
.parentCode(Integer.parseInt(checkParent(cityCode)))
.cityCode(Integer.parseInt(cityCode))
.cityName(cityName)
.build();
return area;
}).collect(Collectors.toList());
lists.forEach(System.out::println);
}
/**
* 用于区分省市区
* @param cityCode
* @return
*/
private static String checkParent(String cityCode){
// 省
if(cityCode.contains("0000")){
return "0";
// 市
}else if (cityCode.contains("00")) {
return String.valueOf(Integer.parseInt(cityCode) / 10000 * 10000);
// 区
}else {
//这里区分直辖市...
if (cityCode.contains("110")) {
return "110000";
}else if (cityCode.contains("120")){
return "120000";
}else if (cityCode.contains("310")){
return "310000";
}else if (cityCode.contains("500")){
return "500000";
}
return String.valueOf(Integer.parseInt(cityCode) / 100 * 100);
}
}
}
最终效果如下:
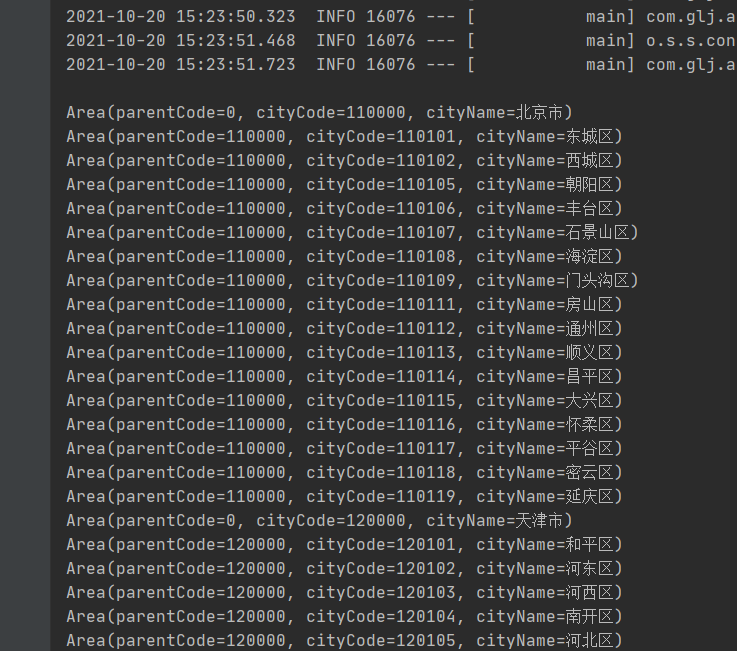
最后,这次的爬虫获取省市区数据还是比较简单,只有简单的几行代码。毕竟民政局的网站也没啥反扒的策略,所以很轻松的就拿到了数据。