本文最后更新于 1432 天前,其中的信息可能已经有所发展或是发生改变。
Prometheus+grafana告警组件单节点部署验证
此次部署是使用docker快速验证部署,主要验证了Prometheus+grafana告警推送邮件和钉钉
使用了2台机器
| IP | 作用 | 备注 |
|---|---|---|
| 10.80.210.56 | prometheus-master | 主要作为主采集节点 |
| 10.80.210.122 | prometheus-node | 主要作为各种xxx-exporter的数据上报节点 |
prometheus-master部署
docker-compose.yml文件内容:
version: '3'
services:
prometheus:
image: prom/prometheus:v2.37.0
container_name: prometheus
hostname: prometheus
restart: always
user: "0"
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/usr/share/prometheus/console_libraries'
- '--web.console.templates=/usr/share/prometheus/consoles'
- '--storage.tsdb.retention.time=7d'
# - '--web.external-url=prometheus'
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- ./prometheus/rules/:/rules/
- ./prometheus/data/:/prometheus/
- /etc/localtime:/etc/localtime:ro
- /etc/timezone:/etc/timezone:ro
ports:
- "9090:9090"
networks:
- monitor
alertmanager:
image: prom/alertmanager:v0.24.0
container_name: alertmanager
hostname: alertmanager
restart: always
user: '0'
volumes:
- /etc/localtime:/etc/localtime:ro
- /etc/timezone:/etc/timezone:ro
- ./alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml
- ./alertmanager/template/:/etc/alertmanager/template/
- ./alertmanager/data/:/alertmanager
ports:
- "9093:9093"
networks:
- monitor
grafana:
image: grafana/grafana:8.5.9
container_name: grafana
hostname: grafana
restart: always
user: "0"
environment:
GF_SECURITY_ADMIN_USER: xinsec
GF_SECURITY_ADMIN_PASSWORD: DB.xinsec
volumes:
- /etc/localtime:/etc/localtime:ro
- /etc/timezone:/etc/timezone:ro
# - ./grafana/config:/etc/grafana
- ./grafana/data:/var/lib/grafana
- ./grafana/log:/var/log/grafana
ports:
- "3000:3000"
networks:
- monitor
node-exporter:
#image: quay.io/prometheus/node-exporter:v1.4.0-rc.0
image: prom/node-exporter:v1.4.0-rc.0
container_name: node-exporter
hostname: node-exporter
restart: always
volumes:
- /etc/localtime:/etc/localtime:ro
- /etc/timezone:/etc/timezone:ro
ports:
- "9100:9100"
networks:
- monitor
pushgateway:
image: prom/pushgateway:v1.4.3
container_name: pushgateway
hostname: pushgateway
restart: always
volumes:
- /etc/localtime:/etc/localtime:ro
- /etc/timezone:/etc/timezone:ro
ports:
- "9091:9091"
networks:
- monitor
cadvisor:
image: google/cadvisor:latest
container_name: cadvisor
hostname: cadvisor
restart: always
volumes:
- /:/rootfs:ro #给cAdvisor对root文件系统的只读权限,以便检测宿主机信息
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
- /dev/disk/:/dev/disk:ro
- /etc/localtime:/etc/localtime:ro
- /etc/timezone:/etc/timezone:ro
ports:
- "18080:8080"
networks:
- monitor
webhook-dingding:
image: timonwong/prometheus-webhook-dingtalk:v1.4.0
container_name: webhook-dingding
hostname: webhook-dingding
restart: always
volumes:
- /data/docker/prometheus/alertmanager/template/dingding.tmpl:/etc/alertmanager/template/dingding.tmpl
- /etc/localtime:/etc/localtime:ro
- /etc/timezone:/etc/timezone:ro
ports:
- "8060:8060"
entrypoint: /bin/prometheus-webhook-dingtalk --template.file="/etc/alertmanager/template/dingding.tmpl" --ding.profile="webhook1=https://oapi.dingtalk.com/robot/send?access_token=xxx"
networks:
- monitor
networks:
monitor:
driver: bridge
说明:
使用了以下容器:
- prometheus
- alertmanager #告警模块
- pushgateway # 程序主动推送需要设置的组件,prometheus 默认是pull模式
- grafana # 展示数据界面
- node-exporter #采集虚拟机指标
- cadvisor #采集docker容器指标
- webhook-dingding #告警推送
目录结构如下:
[root@emqx prometheus]# tree
├── alertmanager
│ ├── alertmanager.yml
│ ├── data
│ └── template
│ ├── dingding.tmpl
│ └── email.tmpl
├── docker-compose.yml
├── grafana
│ ├── data
│ └── log
└── prometheus
├── data
├── prometheus.yml
└── rules
├── mysql_rules.yml
├── node_rules.yml
├── redis_rules.yml
└── vmware_rules.yml
每个容器映射文件:
prometheus
prometheus.yml:
$PWD/prometheus/prometheus.yml
# global模块是全局配置信息,它定义的内容会被scrape_configs模块中的每个Job单独覆盖
global:
scrape_interval: 15s # pull 频率
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
scrape_timeout: 15s # 超时时间
# 告警模块,Prometheus Server发送请求给Alertmanager之前也会触发一次relabel操作
alerting:
alertmanagers:
- static_configs:
- targets:
- '10.80.210.56:9093'
# 告警的规则-定义告警文件
# Prometheus自定义的rule主要分为Recording rule和Alerting rule两类
rule_files:
- "/rules/*"
# A scrape configuration containing exactly one endpoint to scrape:
scrape_configs:
# Job名称很重要,Prometheus会将该名称作为Label追加到抓取的每条时序中
- job_name: 'prometheus'
static_configs: # 监控的主机地址与端口信息
- targets: ['10.80.210.56:9090']
labels:
instance: 'prometheus程序'
- job_name: 'pushgateway'
static_configs:
- targets: [ '10.80.210.56:9091' ]
labels:
instance: 'pushgateway程序'
# #监控主机node信息,依赖插件node_exporter
- job_name: 'node-exporter-服务器信息监控'
static_configs:
- targets: ['10.80.210.122:9100']
labels:
group: '测试docker'
instance: '10.80.210.122-node-exporter'
- targets: ['10.80.210.56:9100']
labels:
group: 'prometheus-master'
instance: '10.80.210.56-node-exporter'
- job_name: 'cadvisor-docker容器监控'
scrape_interval: 120s
static_configs:
- targets: [ '10.80.210.56:18080']
labels:
group: 'prometheus-master'
instance: '10.80.210.56-cadvisor'
- targets: ['10.80.210.122:18080']
labels:
group: '测试docker'
instance: '10.80.210.122-cadvisor'
# 监控主机mysql信息,依赖插件mysql_exporter
- job_name: 'mysql数据库信息监控'
static_configs:
- targets: ['10.80.210.122:9104']
labels:
instance: '10.80.210.122-redis'
# 监控主机redis信息,依赖插件redis-exporter
- job_name: 'redis缓存数据库信息监控'
static_configs:
- targets: ['10.80.210.122:9121']
labels:
instance: '10.80.210.122-redis服务'
# 监控主机java程序信息,需要程序开放端口进行监控
- job_name: 'prometheus-java-demo-java监控'
metrics_path: '/sms/actuator/prometheus'
static_configs:
- targets: ['10.80.210.56:28084']
labels:
instance: 'prometheus-java-demo-java'
# 修改nacos application.properties
# 开启:management.endpoints.web.exposure.include=*
- job_name: 'nacos信息监控'
scrape_interval: 60s
metrics_path: '/nacos/actuator/prometheus'
static_configs:
- targets: ['10.80.210.122:8848']
labels:
instance: '10.80.210.122-nacos'
# 参考:https://blog.csdn.net/qq_37696855/article/details/123484069
- job_name: 'jenkins监控'
metrics_path: '/prometheus'
scheme: http
static_configs:
- targets: [ '10.80.210.171' ]
labels:
instance: '10.80.210.171-jenkens服务'
# 监控主机vmware信息,依赖插件pryorda/vmware_exporter
- job_name: 'vmware_vcenter'
metrics_path: '/metrics'
scheme: http
scrape_interval: 60s
scrape_timeout: 30s
static_configs:
- targets:
- '10.80.210.122:9272'
labels:
host_name: 10.80.211.77
- targets:
- '10.80.210.122:9273'
labels:
host_name: 10.80.210.80
- targets:
- '10.80.210.122:9274'
labels:
host_name: 10.80.210.100
- targets:
- '10.80.210.122:9275'
labels:
host_name: 10.80.210.180
- targets:
- '10.80.210.122:9276'
labels:
host_name: 10.80.210.200
- targets:
- '10.80.210.122:9277'
labels:
host_name: 10.80.210.210
rule告警规则文件
$PWD/prometheus/rules/
mysql_rules.yml
---
groups:
- name: Mysql alert
rules:
- alert: MySQL 运行情况
expr: mysql_up == 0
for: 1m
labels:
severity: 严重
annotations:
summary: "{{ $labels.instance }} MySQL is down"
description: "MySQL database is down."
node_rules.yml
groups:
- name: Node alert
rules:
- alert: job节点状态宕机
expr: up == 0
for: 1m
labels:
severity: 严重
nodename: "{{ $labels.app }}"
annotations:
summary: "{{ $labels.app }}已停止运行超过1分钟!"
description: "节点 {{$labels.instance}} 宕机已超过1分钟请进行人工处理。"
- alert: 服务器实例使用情况
expr: node_load5 > 4
for: 5m
labels:
severity: 警告
nodename: "{{ $labels.app }}"
annotations:
summary: "服务器实例 {{ $labels.app }} 平均负载过高"
description: "主机负载5分钟超过4."
- alert: Memory 使用情况
expr: (1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes))) * 100 > 90
for: 5m # 告警持续时间,超过这个时间才会发送给alertmanager
labels:
severity: 警告
nodename: "{{ $labels.app }}"
annotations:
summary: "服务器实例 {{ $labels.app }}内存使用率过高"
description: "{{ $labels.app }}的内存使用率超过90%,当前使用率[{{ $value }}]."
- alert: CPU 使用情况
expr: 100-avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)*100 > 90
for: 5m
labels:
severity: 警告
nodename: "{{ $labels.app }}"
annotations:
summary: "服务器实例 {{ $labels.app }} cpu使用率过高"
description: "{{ $labels.app }}的cpu使用率超过90%,当前使用率[{{ $value }}]."
- alert: 磁盘容量
expr: 100 - node_filesystem_avail_bytes{fstype=~"ext4|xfs",mountpoint="/"} * 100 / node_filesystem_size_bytes{fstype=~"ext4|xfs",mountpoint="/"} > 80
for: 5m
labels:
severity: 警告
nodename: "{{ $labels.app }}"
annotations:
summary: "服务器实例 {{ $labels.app }} 磁盘使用率过高"
description: "{{ $labels.app }}的disk使用率超过80%,当前使用率[{{ $value }}]."
- alert: IO 性能情况
expr: 100 - (avg(irate(node_disk_io_time_seconds_total[5m])) by(instance)* 100) < 20
for: 2m
labels:
severity: 警告
nodename: "{{ $labels.app }}"
annotations:
summary: "{{$labels.instance}} 流入磁盘IO使用率过高!"
description: "{{$labels.instance }} 流入磁盘IO大于80%(目前使用:{{$value}})"
- alert: TCP会话
expr: node_netstat_Tcp_CurrEstab > 1000
for: 1m
labels:
severity: 警告
nodename: "{{ $labels.app }}"
annotations:
summary: "{{$labels.instance}} TCP_ESTABLISHED过高!"
description: "{{$labels.instance }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)"
- alert: Network 接收(receive)情况
expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 5m
labels:
severity: 提醒
nodename: "{{ $labels.app }}"
annotations:
summary: "{{$labels.instance}} 流入网络带宽过高!"
description: "{{$labels.instance }} 流入网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}"
- alert: Network 传输(transmit)情况
expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400
for: 1m
labels:
severity: 提醒
nodename: "{{ $labels.app }}"
annotations:
summary: "{{$labels.instance}} 流出网络带宽过高!"
description: "{{$labels.instance }}流出网络带宽持续2分钟高于100M. RX带宽使用率{{$value}}"
redis_rules.yml
groups:
# -- 数据库监控规则
- name: Redis alert
rules:
- alert: Redis 内存情况
# redis_memory_used_bytes: redis 已使用的字节
# redis_config_maxmemory: redis 配置文件中最大使用内存字节 默认为0
# expr: 100 * (redis_memory_used_bytes / redis_config_maxmemory) > 90
expr: 100 * (redis_memory_used_bytes / 2147483648) > 90
for: 1m
labels:
severity: 提醒
status: 警告
annotations:
summary: "Redis {{ $labels.instance }} memory userd over 90"
description: "Redis memory used over 90 duration above 1m"
vmware_rules.yml
groups:
- name: Vmware status
rules:
- alert: EXSi主机状态
expr: vmware_host_power_state ==0
for: 5m
labels:
type: lost
severity: 严重
annotations:
summary: "EXSi主机 {{$labels.host_name}} 失联"
description: "EXSi任务 {{$labels.job}} 下的主机 {{$labels.host_name}} 已经超过五分钟没有数据了."
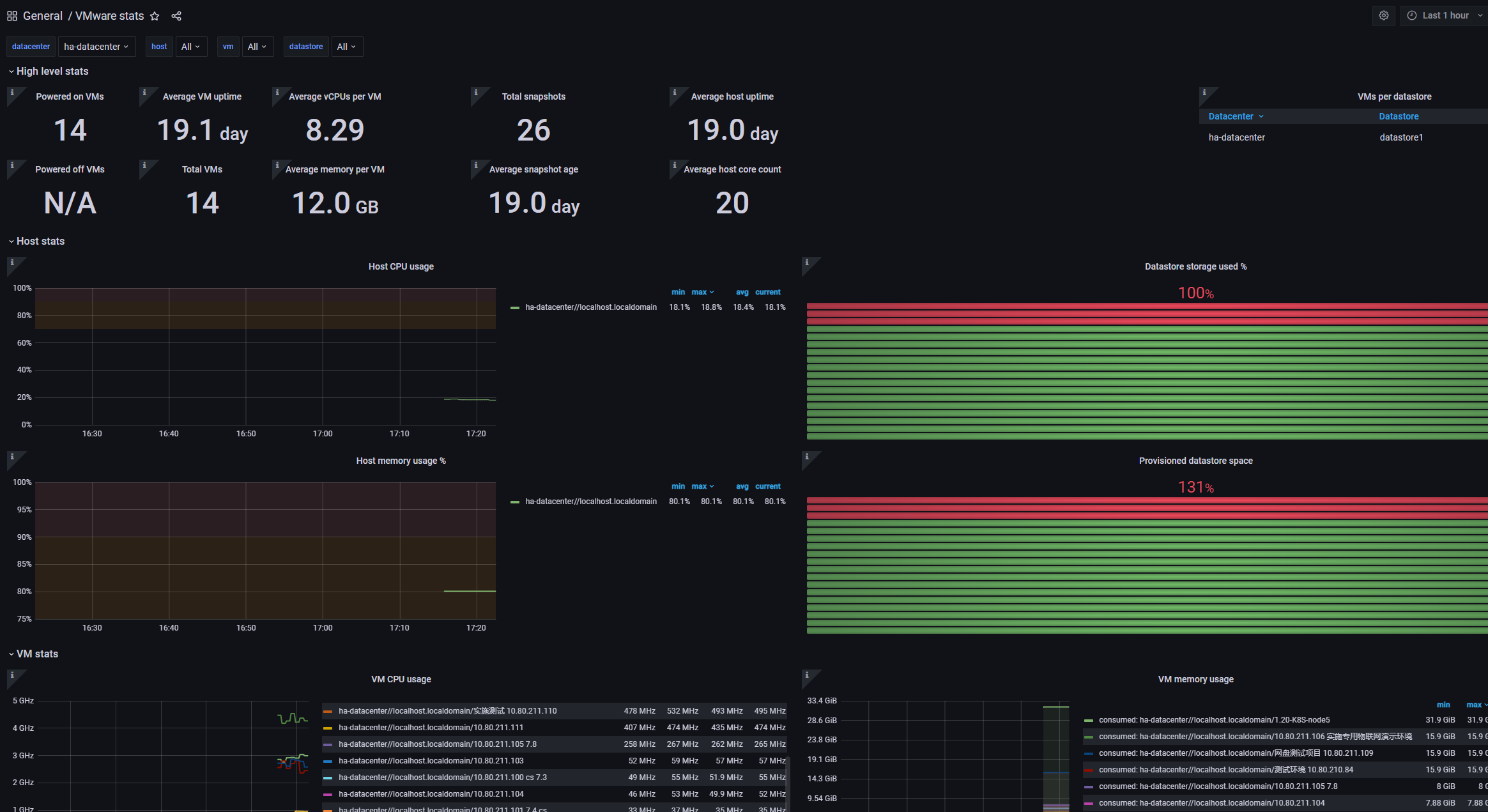
monitor_url: "http://10.80.210.56:3000/d/q1yCDNbWz/vmware-stats?orgId=1"
- alert: 虚拟机内存警告 #虚拟机内存警告模板
expr: vmware_vm_mem_usage_average / 100 >= 80 and vmware_vm_mem_usage_average / 100 < 50
for: 30m
labels:
severity: 警告
annotations:
summary: 虚拟机内存警告 (instance {{ $labels.instance }})
description: 'High memory usage on {{ $labels.instance }}: {{ $value | printf "%.2f"}}%n VALUE = {{ $value }}n VMware_Name = {{ $labels.vm_name }}'
- alert: 虚拟机内存严重不足 #虚拟机内存严重模板
expr: vmware_vm_mem_usage_average / 100 >= 90
for: 30m
labels:
severity: 严重
annotations:
summary: 虚拟机内存严重不足 (instance {{ $labels.instance }})
description: 'High memory usage on {{ $labels.host_name }}: {{ $value | printf "%.2f"}}%n VALUE = {{ $value }}n VMware_Name = {{ $labels.vm_name }}'
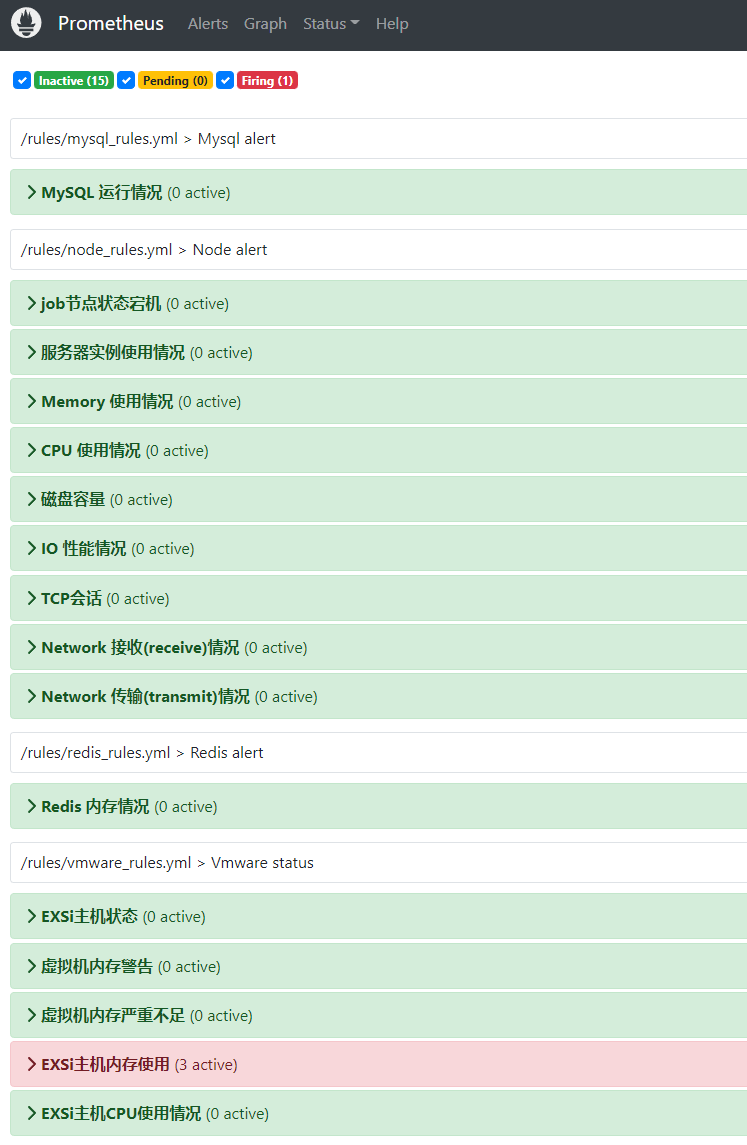
- alert: EXSi主机内存使用
#esxi内存使用百分比模板
expr: ((vmware_host_memory_usage / vmware_host_memory_max) * 100) > 85
for: 5m
labels:
severity: 警告
annotations:
summary: "EXSi主机 {{ $labels.host_name }} 的内存使用率告警"
description: "EXSi主机 {{ $labels.host_name }} 的内存使用率超过 85%, 当前值为: {{ $value }}"
- alert: EXSi主机CPU使用情况
expr: ((vmware_host_cpu_usage / vmware_host_cpu_max) * 100) > 80
for: 5m
labels:
type: cpu
severity: 警告
annotations:
summary: "EXSi主机 {{ $labels.host_name }} 的 CPU 使用率告警"
description: "EXSi主机 {{ $labels.host_name }} CPU 使用率超过 80%, 当前值为: {{ $value }}"
alertmanager
alertmanager.yml
global:
# -邮件通知相关配置
resolve_timeout: 5m
# smtp_smarthost: 'smtp.139.com:465'
# smtp_from: 'xxx@139.com'
# smtp_auth_username: 'xxx@139.com'
# # 授权码
# smtp_auth_password: 'xxx'
# # 不使用加密认证
# smtp_require_tls: false
# 告警模板
templates:
- "/etc/alertmanager/template/*.tmpl"
route:
group_by: ['alertname']
group_wait: 10s
group_interval: 10s
repeat_interval: 30m #30分钟重复一次
receiver: 'ding-hook'
receivers:
# - name: 'mail-receiver'
# email_configs:
# - to: 'xxx@qq.com'
# html: '{{ template "email.to.html" .}}'
# headers: { Subject: "[WARN]告警" }
# send_resolved: true # 表示服务恢复后会收到恢复告警
- name: 'ding-hook'
webhook_configs:
- url: 'http://10.80.210.56:8060/dingtalk/webhook1/send'
send_resolved: true
# 告警抑制规则
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
template告警模板
dingding.tmpl
{{ define "__subject" }}[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}] {{ .GroupLabels.SortedPairs.Values | join " " }} {{ if gt (len .CommonLabels) (len .GroupLabels) }}({{ with .CommonLabels.Remove .GroupLabels.Names }}{{ .Values | join " " }}{{ end }}){{ end }}{{ end }}
{{ define "__alertmanagerURL" }}{{ .ExternalURL }}/#/alerts?receiver={{ .Receiver }}{{ end }}
{{ define "__text_alert_list" }}{{ range . }}
**告警程序**:{{ .Labels.job }}
**告警级别**:{{ .Labels.severity }} 级
**告警类型**:{{ .Labels.alertname }}
**故障主机**: {{ .Labels.instance }}
**告警主题**: {{ .Annotations.summary }}
**告警描叙**: {{ .Annotations.description }}
**告警时间**: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
------------------------
{{ end }}{{ end }}
{{ define "__text_resolve_list" }}{{ range . }}
**恢复程序**:{{ .Labels.alertname }}
**故障主机**: {{ .Labels.instance }}
**告警主题**:{{ .Annotations.summary }}
**恢复描叙**: {{ .Annotations.description }}
**告警时间**: {{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
**恢复时间**: {{ (.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
------------------------
{{ end }}{{ end }}
{{ define "ding.link.title" }}{{ template "__subject" . }}{{ end }}
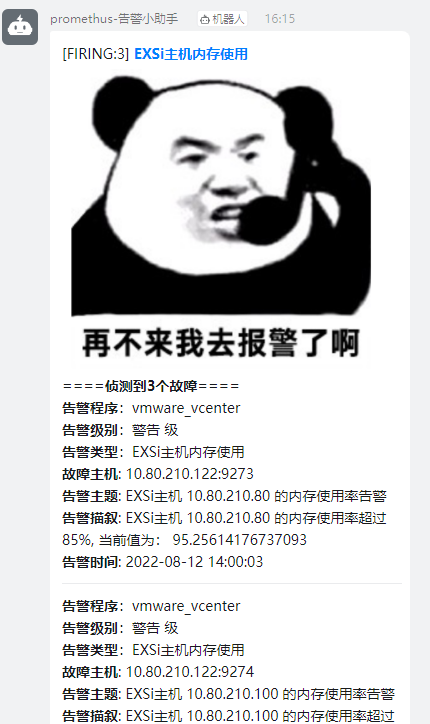
{{ define "ding.link.content" }}#### \[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}\] **[{{ index .GroupLabels "alertname" }}]({{ template "__alertmanagerURL" . }})**
{{ if gt (len .Alerts.Firing) 0 -}}

**====侦测到{{ .Alerts.Firing | len }}个故障====**
{{ template "__text_alert_list" .Alerts.Firing }}
{{- end }}
{{ if gt (len .Alerts.Resolved) 0 -}}
恢复列表:
{{ template "__text_resolve_list" .Alerts.Resolved }}
{{- end }}
{{- end }}
效果:
email.tmpl
{{ define "email.to.html" }}
{{ if gt (len .Alerts.Firing) 0 }}{{ range .Alerts }}
@告警
告警程序: prometheus_alert <br>
告警级别: {{ .Labels.severity }} 级 <br>
告警类型: {{ .Labels.alertname }} <br>
故障主机: {{ .Labels.instance }} <br>
告警主题: {{ .Annotations.summary }} <br>
告警详情: {{ .Annotations.description }} <br>
触发时间: {{ .StartsAt.Format "2006-01-02 15:04:05" }} <br>
{{ end }}
{{ end }}
{{ if gt (len .Alerts.Resolved) 0 }}{{ range .Alerts }}
@恢复:
故障主机:{{ .Labels.instance }} <br>
告警主题:{{ .Annotations.summary }} <br>
恢复时间: {{ .EndsAt.Format "2006-01-02 15:04:05" }} <br>
{{ end }}
{{ end }}
{{ end }}

prometheus-node部署
docker-compose.yml文件内容:
version: '3'
services:
node-exporter:
image: prom/node-exporter:v1.4.0-rc.0
container_name: node-exporter
hostname: node-exporter
restart: always
volumes:
- /etc/localtime:/etc/localtime:ro
- /etc/timezone:/etc/timezone:ro
ports:
- "9100:9100"
networks:
- monitor
mysqld-exporter:
image: prom/mysqld-exporter:v0.13.0
container_name: mysqld-exporter
hostname: mysqld-exporter
restart: always
volumes:
- /etc/localtime:/etc/localtime:ro
- /etc/timezone:/etc/timezone:ro
environment:
# 数据库账号:密码@ip:端口/
DATA_SOURCE_NAME: user:passwd@(ip:port)/
ports:
- "9104:9104"
networks:
- monitor
redis-exporter:
image: bitnami/redis-exporter:1.43.0
container_name: redis-exporter
hostname: redis-exporter
restart: always
volumes:
- /etc/localtime:/etc/localtime:ro
- /etc/timezone:/etc/timezone:ro
environment:
redis.addr: redis://10.80.210.122:6379
redis.password: abc123456
command: #参考:https://github.com/bitnami/bitnami-docker-redis-exporter https://github.com/oliver006/redis_exporter
- '--redis.addr=redis://10.80.210.122:6379'
- '--redis.password=abc123456'
ports:
- "9121:9121"
networks:
- monitor
cadvisor:
image: google/cadvisor:latest
container_name: cadvisor
hostname: cadvisor
restart: always
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
- /etc/localtime:/etc/localtime:ro
- /etc/timezone:/etc/timezone:ro
ports:
- "18080:8080"
networks:
- monitor
vmware-exporter-77:
image: pryorda/vmware_exporter:v0.18.3
container_name: vmware-exporter-77
restart: unless-stopped
ports:
- '9272:9272'
environment:
VSPHERE_HOST: "10.80.211.77"
VSPHERE_IGNORE_SSL: "True"
VSPHERE_USER: "user"
VSPHERE_PASSWORD: "passwd"
volumes:
- /etc/localtime:/etc/localtime:ro
- /etc/timezone:/etc/timezone:ro
networks:
- monitor
networks:
monitor:
driver: bridge
说明:
使用了以下容器:
- node-exporter #采集虚拟机指标
- mysqld-exporter #mysql数据库采集
- redis-exporter # redis数据采集
- cadvisor #采集docker容器指标
- vmware-exporter #vm虚拟机采集
Grafana常用模板
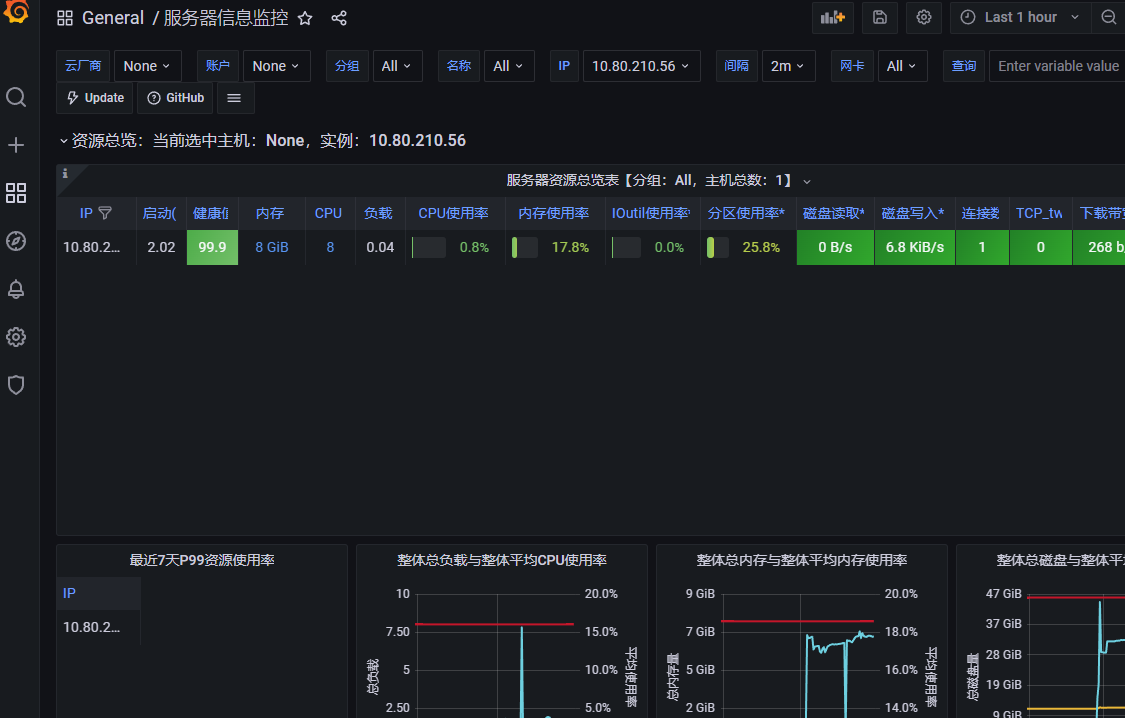
服务器系统性能监控:8919
微服务性能监控:4701 或 汉化:12856 或 SpringBoot监控:12900
Docker环境性能监控:893
nacos性能监控:13221
mysql性能监控:9362
nginx性能监控:9614
neo4j性能监控:10371(企业版才支持)
Redis监控:763
tomcat监控:暂时忽悠
HikariCP数据源监控:6083/Druid数据源监控:11157
Jenkins监控:9964
VMware 监控:11243