Kubernetes-部署Promehteus监控
本次使用kube-prometheus也就是网上常用的Prometheus Operator快速部署监控,官方文档说明:https://github.com/prometheus-operator/kube-prometheus
Prometheus Operator VS kube-prometheus
目前Prometheus Operator已经不包含完整功能,完整的解决方案已经变为kube-prometheus。
- Prometheus Operator 是CoreOS的一个开源项目,用来增强Prometheus在Kubernetes中的管理运维能力。利用Kubernetes的自定义资源定义 (Custom Resource Definition)的特性,实现声明式管理运维Prometheus监控告警系统。
-
kube-prometheus 为基于 Prometheus 和 Prometheus Operator 的完整集群监控堆栈提供示例配置。这包括部署多个 Prometheus 和 Alertmanager 实例、指标导出器(例如用于收集节点指标的 node_exporter)、抓取将 Prometheus 链接到各种指标端点的目标配置,以及用于通知集群中潜在问题的示例警报规则。
-
两个项目的关系:前者只包含了Prometheus Operator,后者既包含了Operator,又包含了Prometheus相关组件的部署及常用的Prometheus自定义监控,具体包含下面的组件
-
- The Prometheus Operator:创建CRD自定义的资源对象
- Highly available Prometheus:创建高可用的Prometheus
- Highly available Alertmanager:创建高可用的告警组件
- Prometheus node-exporter:创建主机的监控组件
- Prometheus Adapter for Kubernetes Metrics APIs:创建自定义监控的指标工具(例如可以通过nginx的request来进行应用的自动伸缩)
- kube-state-metrics:监控k8s相关资源对象的状态指标
- Grafana:进行图像展示
安装kube-prometheus
下载kube-prometheus
根据k8s版本的下载对应Releases
本次对应下载的版本是:v0.9.0
下图红框为部署的yaml文件
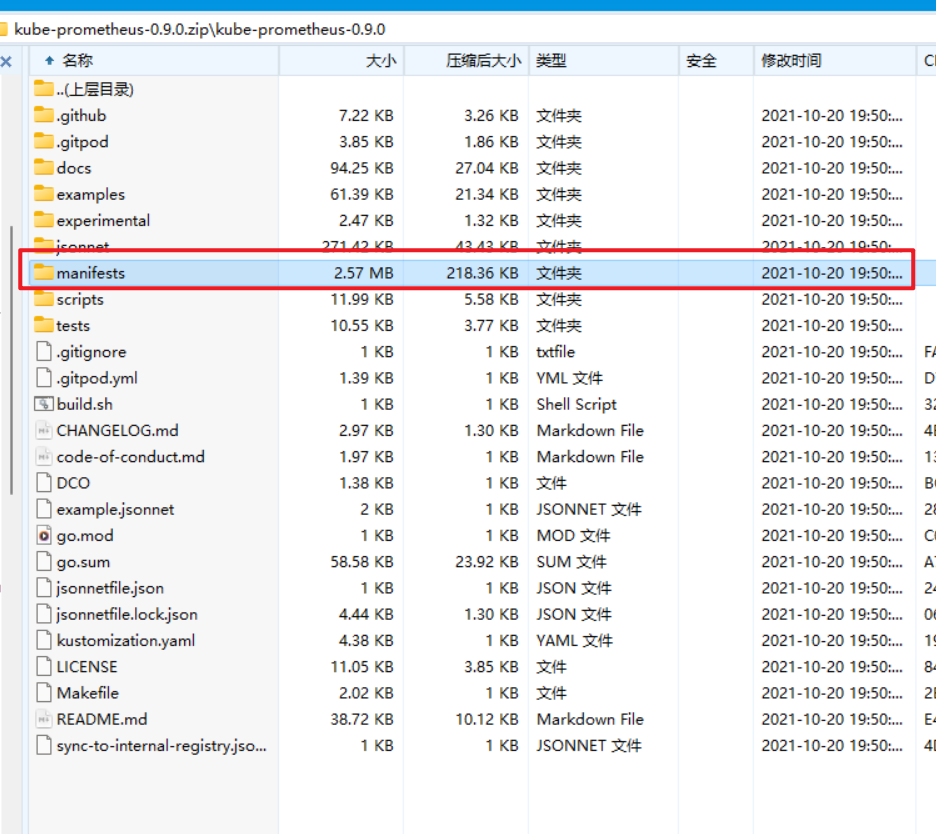
修改镜像源
因为生产环境是内网环境,需要提前准备好镜像,并且放到harbor镜像仓库中。
执行:grep -rn 'image: ' *即可查看需要修改的镜像内容
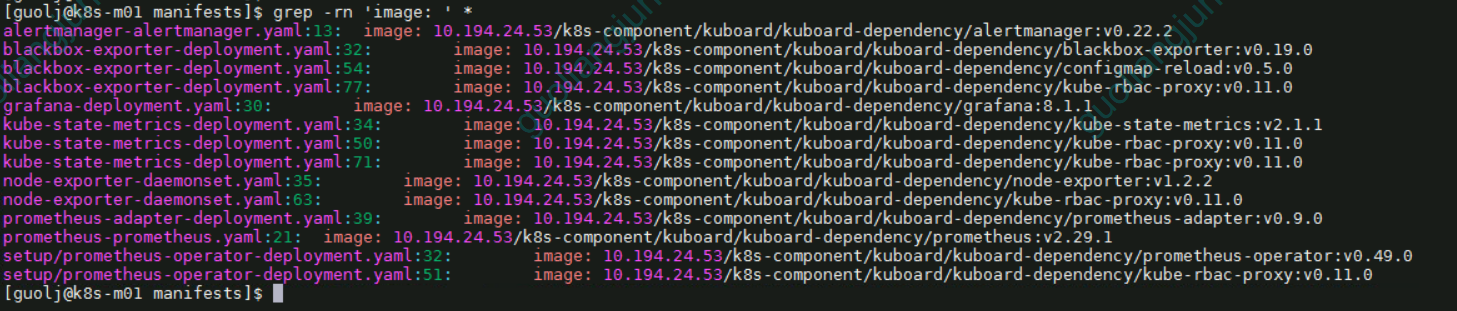
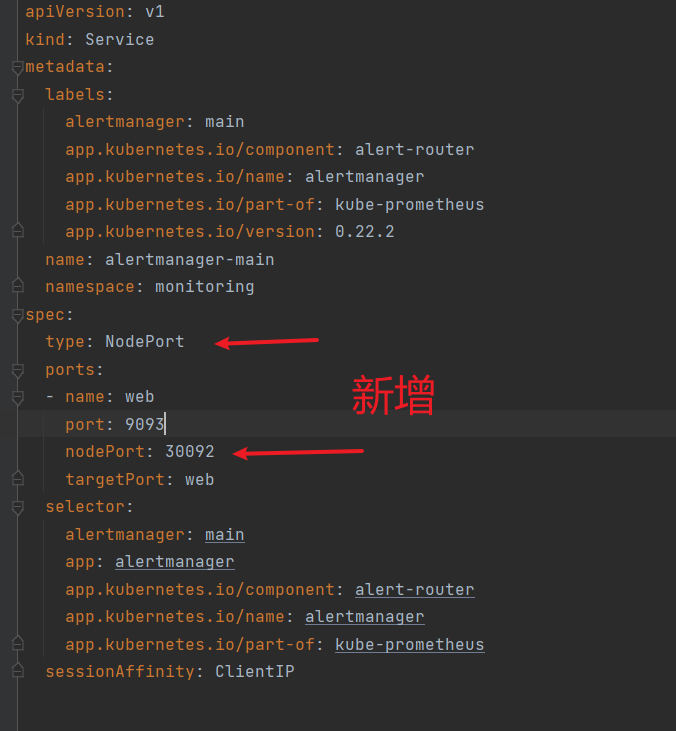
修改类型为NodePort
为了可以从外部访问prometheus,alertmanager,grafana,我们这里修改promethes,alertmanager,grafana的service类型为NodePort类型。
修改prometheus的service
修改prometheus-service.yaml
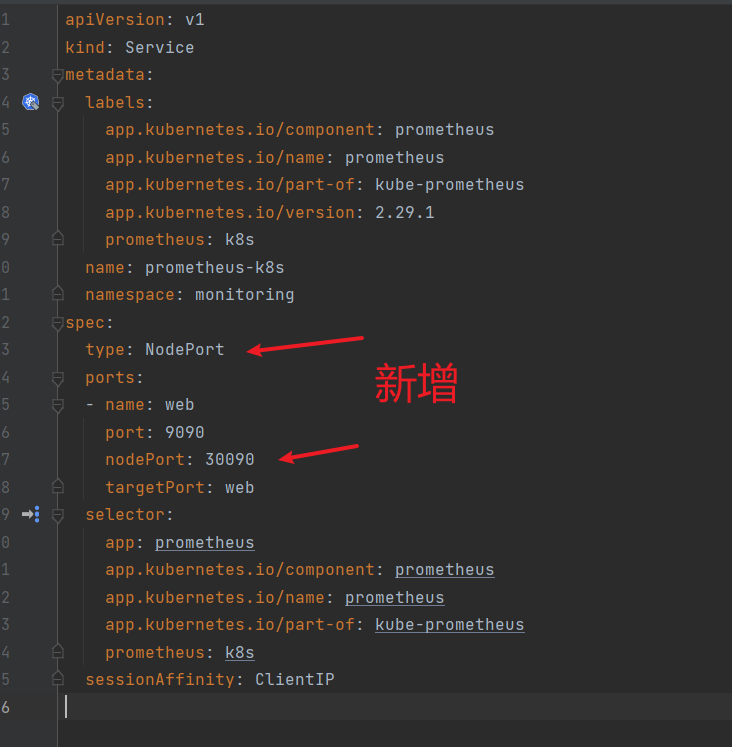
修改grafana的service
修改grafana-service.yaml
修改alertmanager的service
修改alertmanager-service.yaml
安装CRD和prometheus-operator
CustomResourceDefinition:自定义资源
进入manifests文件路径
执行:kubectl apply -f setup/
安装prometheus, alertmanager, grafana, kube-state-metrics, node-exporter等资源
执行:kubectl apply -f .
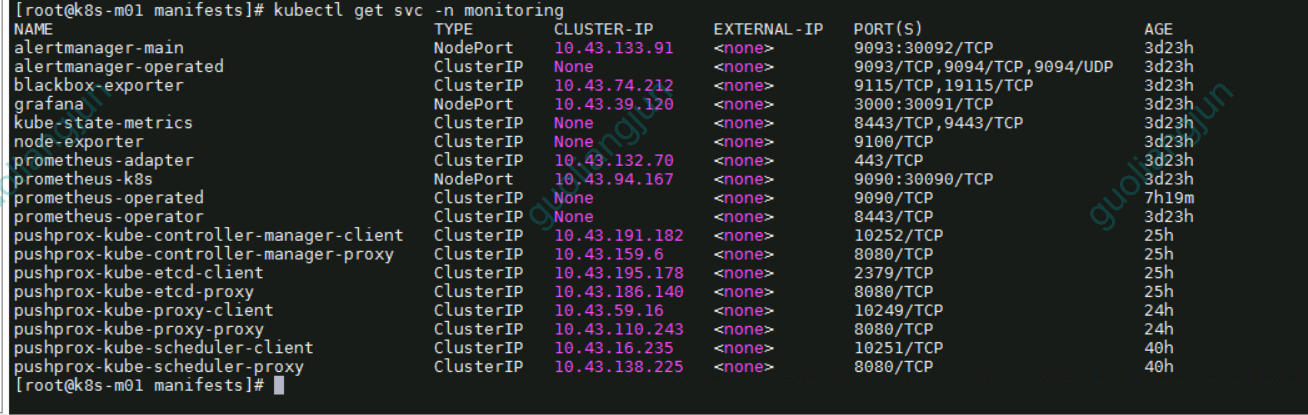
稍等一段时间再查看,查看命名空间monitoring下面的pod状态,直到monitoring命名空间下所有pod都变为running状态,就大功告成了。
[root@k8s-m01 manifests]# kubectl get pod -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 3d23h
alertmanager-main-1 2/2 Running 0 3d23h
alertmanager-main-2 2/2 Running 0 3d23h
blackbox-exporter-7c75745887-s6qr9 3/3 Running 0 3d23h
grafana-d6c4d689c-qtsf2 1/1 Running 0 3d23h
kube-state-metrics-558c88dcf8-lclbq 3/3 Running 0 3d23h
node-exporter-2qqrn 2/2 Running 0 3d23h
node-exporter-c6dbd 2/2 Running 0 3d23h
node-exporter-llwlt 2/2 Running 0 3d23h
node-exporter-mhc27 2/2 Running 0 3d23h
node-exporter-tllch 2/2 Running 0 3d23h
prometheus-adapter-668bb8b6d-cs2jz 1/1 Running 0 3d22h
prometheus-adapter-668bb8b6d-gswtb 1/1 Running 0 3d22h
prometheus-k8s-0 2/2 Running 0 7h17m
prometheus-operator-69f74db686-247kx 2/2 Running 0 3d23h
组件说明
- node_exporter:用来监控运算节点上的宿主机的资源信息,需要部署到所有运算节点
- kube-state-metric:prometheus采集k8s资源数据的exporter,能够采集绝大多数k8s内置资源的相关数据,例如pod、deploy、service等等。同时它也提供自己的数据,主要是资源采集个数和采集发生的异常次数统计
- blackbox_exporter:监控业务容器存活性
- prometheus-adapter:由于本身prometheus属于第三方的 解决方案,原生的k8s系统并不能对Prometheus的自定义指标进行解析,就需要借助于k8s-prometheus-adapter将这些指标数据查询接口转换为标准的Kubernetes自定义指标。
验证
浏览器访问
prometheus:http://vip:30090/
grafana:http://vip:30091/login #默认账号/密码:admin/admin
alertmanager:http://vip:30092/
数据持久化
使用kube-prometheus安装的prometheus,默认是没有将数据持久化的,也是就是pod 重启数据就丢失了,因此kube-prometheus数据必须做持久化
默认为NFS 存储的 StorageClass 配置
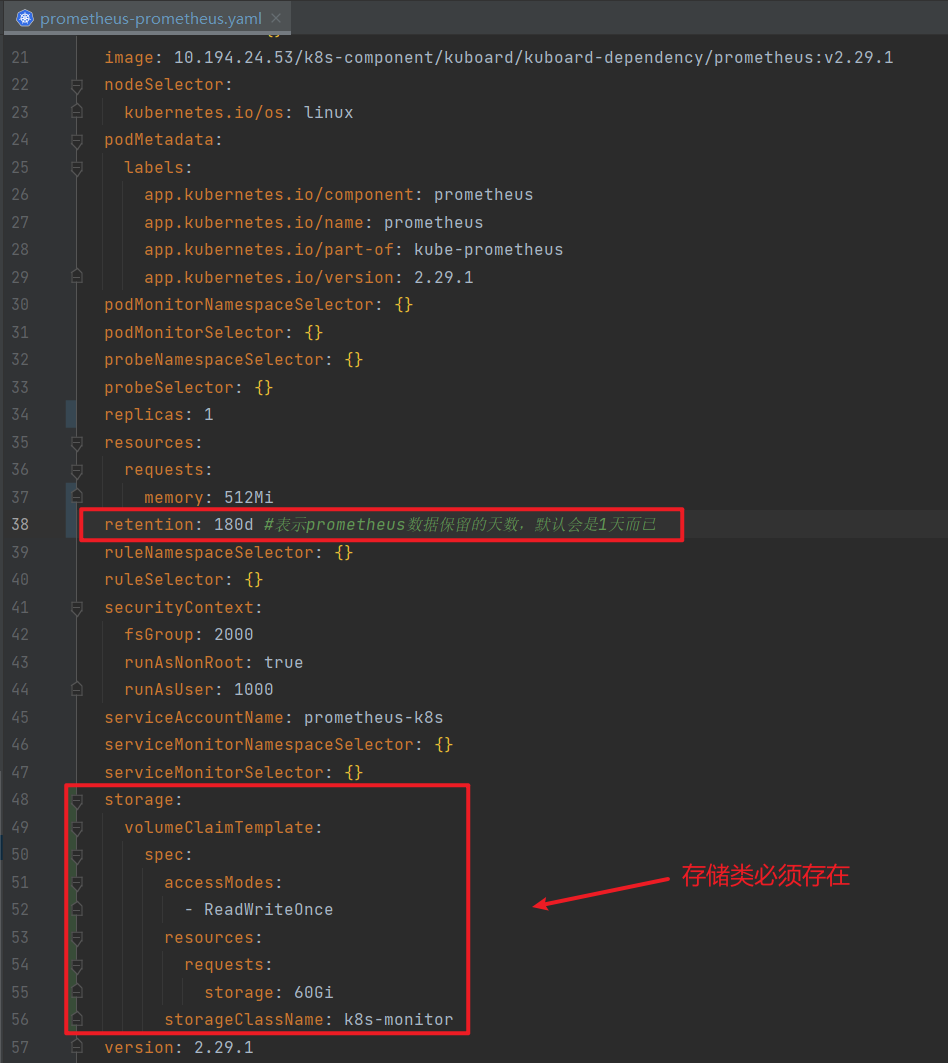
prometheus持久化设置
prometheus-server 默认情况下没有配置数据持久化。所以我们需要做持久化存储。
当初创建kube-prometheus的yaml文件里面并没有创建StatefulSet资源。官方定义了一种叫做prometheus的资源,该资源创建了StatefulSet
修改prometheus-prometheus.yaml文件
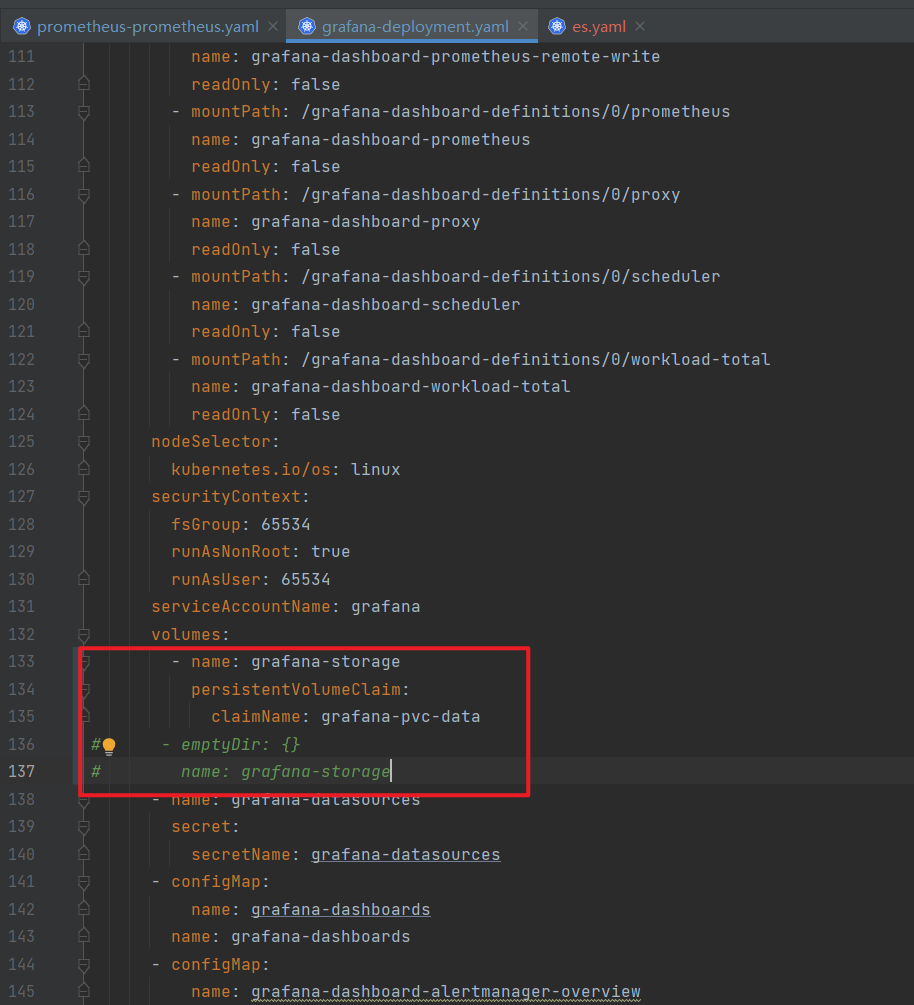
Grafana持久化设置
创建 grafana-pvc.yaml 文件
由于 Grafana 是部署模式为 Deployment,所以我们提前为其创建一个 grafana-pvc.yaml文件
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: grafana-pvc-data
namespace: monitoring #---指定namespace为monitoring
spec:
storageClassName: k8s-monitor #---指定StorageClass
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 40Gi
编辑grafana的yaml文件
kube-prometheus 部署完成后出现的告警问题
在kube-promethesu部署完成之后,会出现KubeControllerManagerDown、KubeProxyDown、KubeSchedulerDown、Watchdog四个告警
因为K8S集群使用rke部署的,k8s组件基本上都是docker跑,
KubeControllerManagerDown、KubeProxyDown、KubeSchedulerDown这三个需要额外添加监控
KubeControllerManagerDown/KubeSchedulerDown/KubeProxyDown/告警
这三个告警都是Prometheus无法发现目标数据导致的告警。
RKE部署k8s解决
需要使用pushprox-client和pushprox-proxy做中转映射,具体yaml文件已经做记录
二进制或者kubeadm部署
参考:https://blog.tearth.cn/index.php/archives/37/
Watchdog
查看Watchdog的告警描述:This is an alert meant to ensure that the entire alerting pipeline is functional. This alert is always firing, therefore it should always be firing in Alertmanager and always fire against a receiver. There are integrations with various notification mechanisms that send a notification when this alert is not firing. For example the "DeadMansSnitch" integration in PagerDuty.,简单来说,这个告警是为了保证告警功能可以正常使用,如果这个告警消失,那就表示告警系统出了问题。如果不需要这个功能,可以修改prometheus目录中的相关文件kubePrometheus-prometheusRule.yaml,注释或删除相关的内容即可。