本文最后更新于 618 天前,其中的信息可能已经有所发展或是发生改变。
工具介绍
一个根据配置进行定时执行mq amqsmon命令,生成对应时段的mq 统计数据.
环境搭建说明:
- 开发环境为:python2
- 经过测试可在
centos 6.5/6.9/7.x系统默认的python版本正常运行
配置过程
配置过程分为
1. mq 队列开启统计
2. 代码配置config.json文件,并部署到对应虚拟机下
3. 配置cdc收集输出的文件
mq 队列开启统计
开启队列管理统计监视
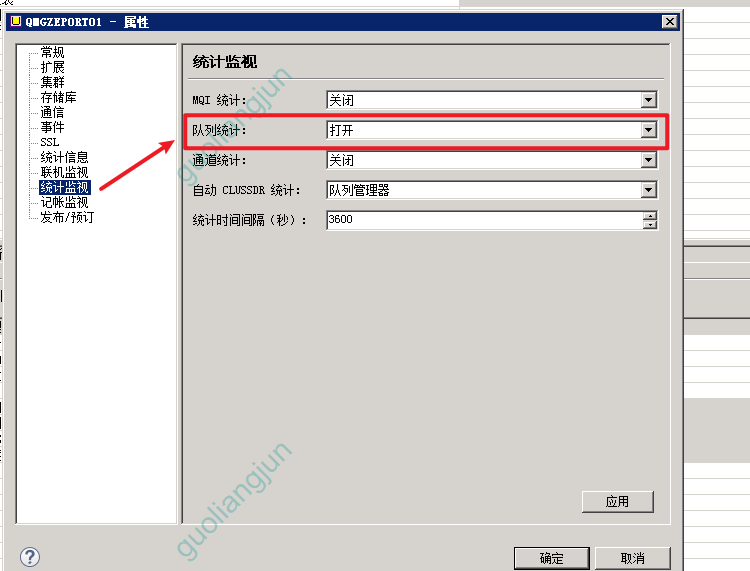
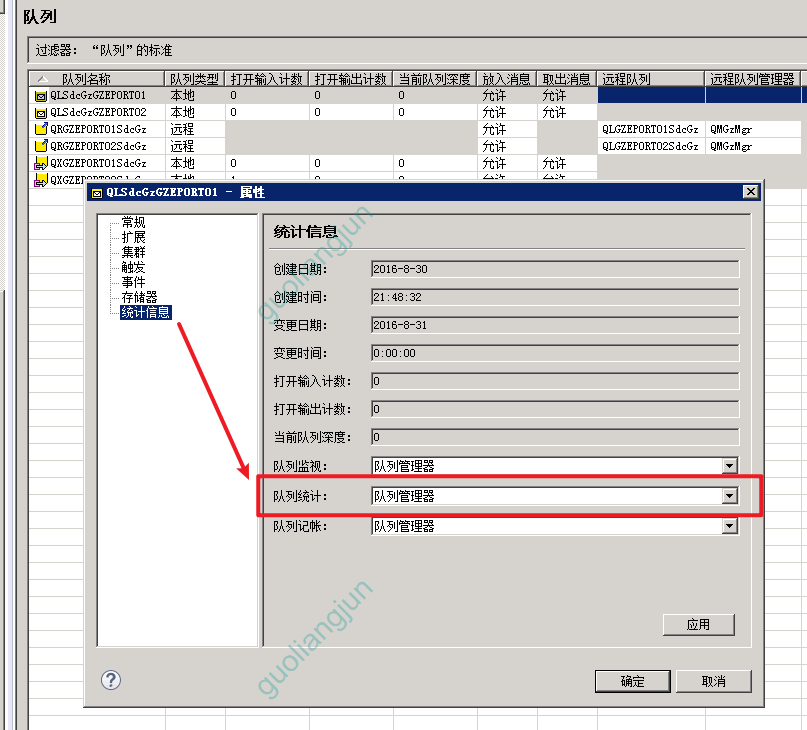
检查队列统计是否开启
代码配置config.json文件,并部署到对应虚拟机下
config.json配置文件说明
[
{
"qm_name": "QMGZEPORT01",// 队列管理器名称
"queue_name": "QLSdcGzGZEPORT01,QLSdcGzGZEPORT02",// 队列名称,多个队列用英文逗号(,)隔开
"center_name": "广州海关",// 对外公司或者海关或者中心,如:广州海关/深圳电子口岸等
"data_type": "receiving",// 队列数据类型,接收或者发送
"delete_history": true // 数据是否保留,暂时未启用
},
{
"qm_name": "QMGZEPORT01",
"queue_name": "QXGZEPORT01SdcGz,QXGZEPORT02SdcGz",
"center_name": "广州海关",
"data_type": "sending",
"delete_history": true
}
]
部署代码
默认部署到/AppHome/ibmmq_count_py路径下,如果部署到其他路径需要在start.sh脚本修改file_path参数
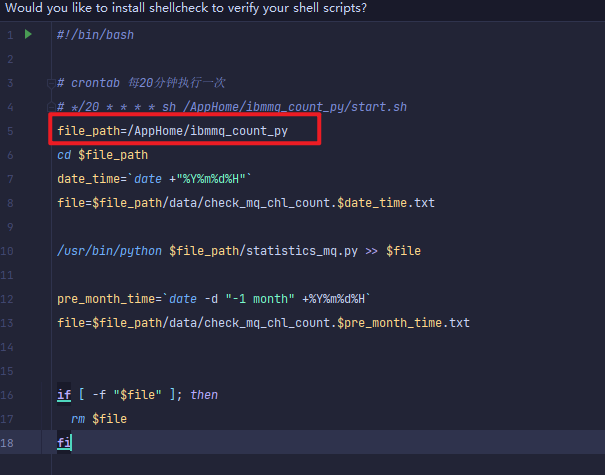
crontab设置定时执行
*/20 * * * * sh /AppHome/ibmmq_count_py/start.sh
配置cdc收集输出的文件
1.日志路径为start.sh输出结果路径文件
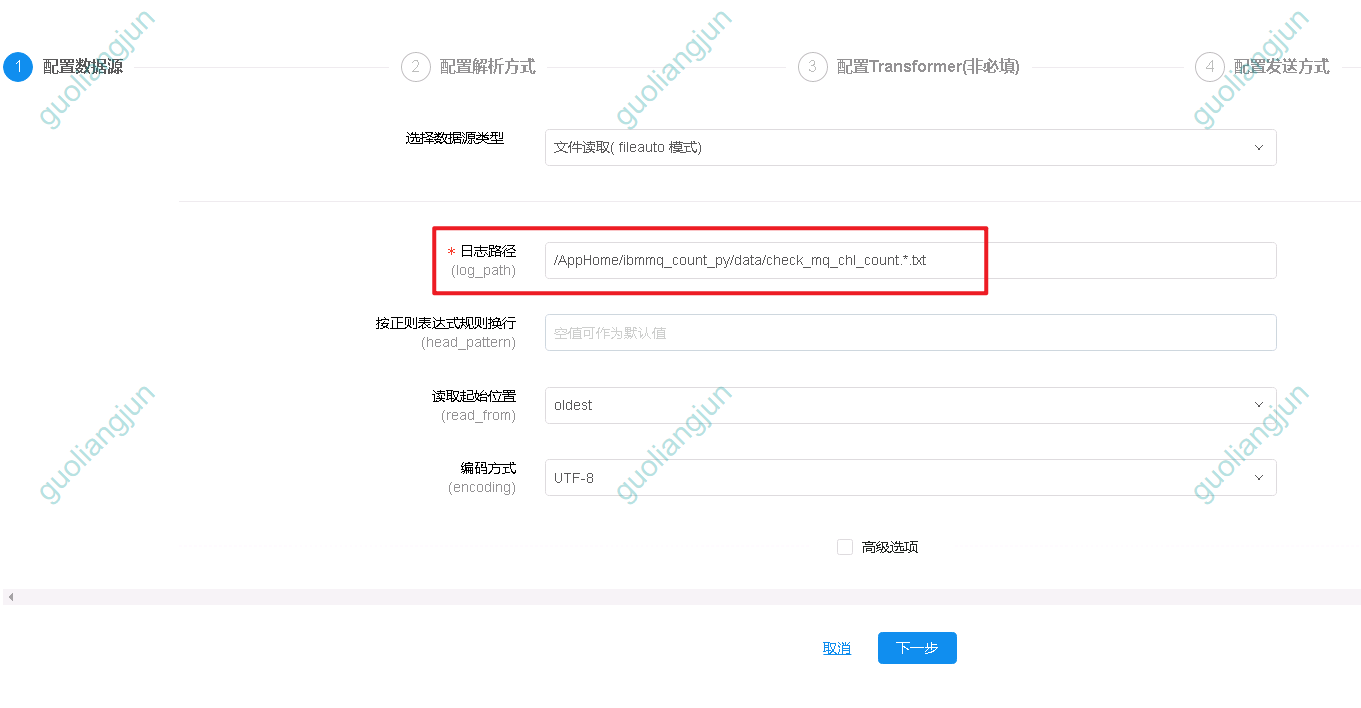
2.配置cdc标签


3.配置数据源,默认kafka
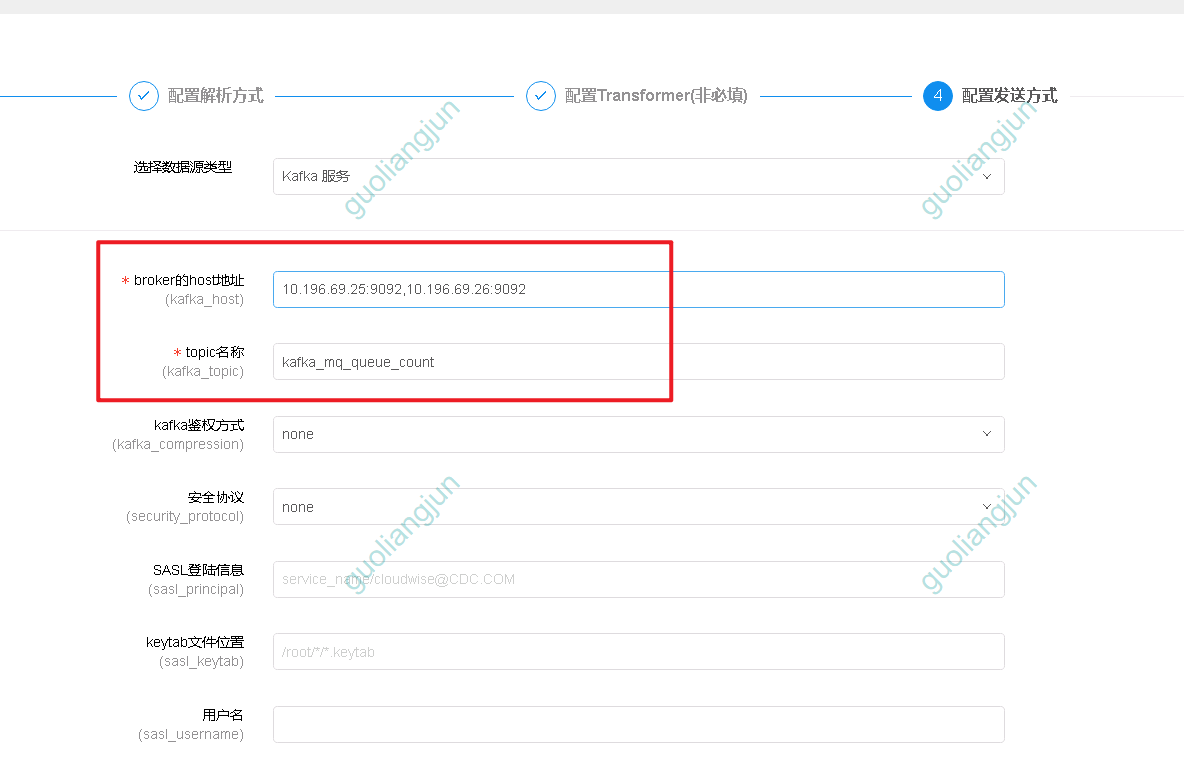
至此…配置已完毕~等待程序入库。
代码statistics_mq.py
#!/usr/bin/python
# -*- coding: utf-8 -*-
"""
支持系统默认自带的python2.6运行.
python statistics_mq.py
命令参考:https://www.ibm.com/docs/zh/ibm-mq/7.5?topic=information-amqsmon-examples#q037410___q037410_1
PutCount 生产
GetCount 消费
"""
import datetime
import io
import json
import os
# python2
import sys
reload(sys)
sys.setdefaultencoding('utf8')
separator_str = ','
def str2num(data):
list_count = data.strip().replace("[", "").replace("]", "").split(", ")
int_list_count = [int(x) for x in list_count]
return int_list_count
def json_read(path):
"""
读取json文件
:param path:
:return:
"""
# python 3
# with open(path, 'r', encoding='utf8') as fp:
# json_data = json.load(fp)
# return json_data
# python 2
try:
fp = io.open(path, "r", encoding='utf-8')
json_data = json.load(fp)
return json_data
except Exception:
pass
finally:
fp.close()
def do_main(qms):
# 当前时间...
now_time = datetime.datetime.now()
cur_hour_str = datetime.datetime.strftime(now_time, "%Y-%m-%d %H")
pre_hour_str = (now_time + datetime.timedelta(hours=-2)).strftime("%Y-%m-%d %H")
arr_qm_name = []
for qm_info in qms:
qm_name = qm_info['qm_name']
queue_name = qm_info['queue_name']
center_name = qm_info['center_name']
data_type = qm_info['data_type']
arr_qm_name.append(qm_name)
for q in queue_name.split(","):
text = os.popen("/opt/mqm/samp/bin/amqsmon -m %s -q %s -t statistics -b -s \"%s\" -e \"%s\" "
% (qm_name, q, pre_hour_str, cur_hour_str)).readlines()
str_data = ""
qn_ql = ""
if len(text) > 2:
for line in text:
line_list = line.strip().split(':')
if len(line_list) == 2:
if line_list[0] == 'QueueName':
qn_ql = qm_name + separator_str + line_list[1].strip().replace("'", "") + separator_str + center_name + separator_str + data_type + separator_str
if line_list[0] == 'PutCount':
str_data += qn_ql + str(sum(str2num(line_list[1]))) + separator_str
if line_list[0] == 'GetCount':
str_data += str(sum(str2num(line_list[1]))) + separator_str
str_data += cur_hour_str + separator_str + pre_hour_str + os.linesep
#print(str_data)
if len(str_data) > 0:
print(str_data)
else:
str_data = qm_name + separator_str + q + separator_str + center_name + separator_str + data_type + separator_str + "0" + separator_str + "0" + separator_str + cur_hour_str + separator_str + pre_hour_str + os.linesep
print(str_data)
# GZYBRK_4,SYSTEM.CLUSTER.TRANSMIT.QUEUE,xx中心,0,0
# 这里再循环一次是存在 一个队列管理器下,有多个分中心数据。
# 避免相同队列名称 上一次循环直接消费队列数据,造成后续的无数据消费...
for qm_name in arr_qm_name:
# qm_name = qm_info['qm_name']
# delete_history = qm_info['delete_history']
# if delete_history:
os.popen("/opt/mqm/samp/bin/amqsmon -m %s -t statistics -s \"%s\" -e \"%s\" "
% (qm_name, pre_hour_str, cur_hour_str))
if __name__ == "__main__":
config_info = json_read('config.json')
if config_info is not None:
do_main(config_info)
# try:
# config_info = json_read('config.json')
# if config_info is not None:
# do_main(config_info)
# except Exception:
# print('json 配置文件有误.')
start.sh定时执行代码
#!/bin/bash
# crontab 每20分钟执行一次
# */20 * * * * sh /AppHome/ibmmq_count_py/start.sh
file_path=/AppHome/ibmmq_count_py
cd $file_path
date_time=`date +"%Y%m%d%H"`
file=$file_path/data/check_mq_chl_count.$date_time.txt
/usr/bin/python $file_path/statistics_mq.py >> $file
pre_month_time=`date -d "-1 month" +%Y%m%d%H`
file=$file_path/data/check_mq_chl_count.$pre_month_time.txt
if [ -f "$file" ]; then
rm $file
fi