系统:centos 7
软件包:
jdk-8u131-linux-x64.rpm
zookeeper-3.4.12.tar.gz
kafka_2.11-2.2.2.tgz
1.演示安装服务器地址&名称:
172.42.100.7 hadoop4
172.42.100.8 hadoop5
172.42.100.9 hadoop6
2.安装jdk(每台都需安装)
2.1.上传文件到某一个服务器,通过scp使得每一台服务器都有文件
scp -r jdk-8u131-linux-x64.rpm root@hadoop5:/home/
2.2.查找安装过的java包
rpm -qa | grep java
如果查出来有 运行 rpm -e –nodeps 查出来的包名(将已安装java全部卸载)
2.3.安装java rpm包(每台机器执行)
ps:如果已经存在jdk1.8的可忽略
rpm -ivh jdk-8u131-linux-x64.rpm
2.4.验证是否安装成功
java -version
or
which java
3.搭建zookeeper集群
3.1.下载地址:
https://mirrors.huaweicloud.com/apache/zookeeper/zookeeper-3.4.12/
教程用的是zookeeper-3.4.12,区别应该不大,清华源最新已经是3.4.12…
3.2.所有节点安装zookeeper
可预先在一台服务器上配置完文件,再复制到其他集群服务器上
#文件都放到/data/kafka_test/
如没有kafka_test文件需要创建
mkdir /data/kafka_test
#将zookeeper解压到安装目录
tar -zxvf zookeeper-3.4.12.tar.gz
#更换文件夹名称
mv zookeeper-3.4.12 zookeeper
#新建日志目录
mkdir -p /data/kafka_test/zookeeper/dataLog
#新建保存数据的目录
mkdir -p /data/kafka_test/zookeeper/data
#配置环境变量并刷新
#vi /etc/profile
export ZK_HOME=/data/kafka_test/zookeeper
export PATH=$PATH:$ZK_HOME/bin
#刷新一下环境变量
source /etc/profile
3.3.所有节点配置zookeeper配置文件
可预先在一台服务器上配置完文件,再复制到其他集群服务器上
#进入配置文件文件夹
cd /data/kafka_test/zookeeper/conf/
#复制文件
cp -f zoo_sample.cfg zoo.cfg
#修改文件配置
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/data/kafka_test/zookeeper/data/
dataLogDir=/data/kafka_test/zookeeper/dataLog/
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.0=hadoop4:2888:3888
server.1=hadoop5:2888:3888
server.2=hadoop6:2888:3888
ps:
复制文件后需要就改的地方其实就如下:
#追加或修改
dataDir=/data/kafka_test/zookeeper/data/
dataLogDir=/data/kafka_test/zookeeper/dataLog/
#追加服务器集群信息
server.0=hadoop4:2888:3888
server.1=hadoop5:2888:3888
server.2=hadoop6:2888:3888
第一个端口是master和slave之间的通信端口,默认是2888,第二个端口是leader选举的端口,集群刚启动的时候选举或者leader挂掉之后进行新的选举的端口默认
#配置myid
# echo "0" > /data/kafka_test/zookeeper/data/myid #server0配置,各节点不同,跟上面配置server.0的号码一样
# echo "1" > /data/kafka_test/zookeeper/data/myid #server1配置,各节点不同,跟上面配置server.1的号码一样
# echo "2" > /data/kafka_test/zookeeper/data/myid #server2配置,各节点不同,跟上面配置server.2的号码一样
3.4.修改启动脚本–>zkServer.sh
cd /data/kafka_test/zookeeper/bin/
vi zkServer.sh
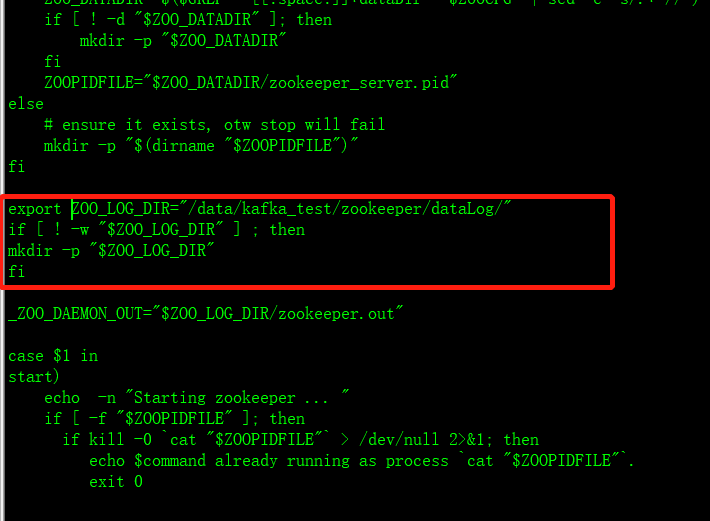
查找到if [ ! -w “$ZOO_LOG_DIR” ] ; then前追加一段:
export ZOO_LOG_DIR=”/data/kafka_test/zookeeper/dataLog/”
3.5.启动停止zookeeper命令
#启动
zkServer.sh start
#shell脚本同时启动
#! /bin/bash
ssh root@hadoop4 zkServer.sh start
ssh root@hadoop5 zkServer.sh start
ssh root@hadoop6 zkServer.sh start
#停止
zkServer.sh stop
#shell脚本同时关闭
#! /bin/bash
ssh root@hadoop4 zkServer.sh stop
ssh root@hadoop5 zkServer.sh stop
ssh root@hadoop6 zkServer.sh stop
#连接集群
zkCli.sh
4.搭建kafka集群
4.1.下载地址:
https://mirrors.huaweicloud.com/apache/kafka/2.2.2/
教程用的是kafka_2.11-2.2.2.tgz
4.2.所有节点上搭建kafka
可预先在一台服务器上配置完文件,再复制到其他集群服务器上
#文件都放到/data/kafka_test/
如没有kafka_test文件需要创建
mkdir /data/kafka_test
#新建kafka日志目录
mkdir -p /data/kafka-data
#解压kafka
tar -zxvf kafka_2.11-2.2.2.tgz
#更换文件夹名称
mv kafka_2.11-2.2.2 kafka
#配置环境变量并刷新
#vi /etc/profile
# kafka
export KAFKA_HOME=/data/kafka_test/kafka
export PATH=$PATH:$KAFKA_HOME/bin
#刷新一下环境变量
source /etc/profile
#备份并修改kafka配置文件:server.properties
cd /data/kafka_test/kafka/config/
mv server.properties server_bak.properties
#新建server.properties 并追加一下内容:
####################
#kafka broker config
####################
#broker config
#每一个broker在集群中的唯一标示,要求是正数
broker.id=0
# 选择启用删除主题功能,默认false
delete.topic.enable=true
# 一个topic ,默认分区的replication个数 ,不得大于集群中broker的个数
default.replication.factor=2
auto.create.topics.enable=false
# 套接字服务器连接的地址
listeners=PLAINTEXT://:9092
num.network.threads=10
num.io.threads=36
socket.send.buffer.bytes=1048576
socket.receive.buffer.bytes=1048576
socket.request.max.bytes=104857600
message.max.bytes=10485760
# replicas每次获取数据的最大大小
replica.fetch.max.bytes=12582912
#kafka数据的存放地址
log.dirs=/data/kafka-data
#segment文件保留的最长时间(小时),超时将被删除
log.retention.hours=12
log.flush.interval.messages=20000
#消息体的最大大小,单位是字节
log.segment.bytes=1073741824
#定期检查segment文件有没有达到1G(单位毫秒)
log.retention.check.interval.ms=120000
num.recovery.threads.per.data.dir=6
#zookeeper集群的地址,可以是多个
zookeeper.connect=hadoop4:2181,hadoop5:2181,hadoop6:2181
zookeeper.connection.timeout.ms=6000
ps:broker.id 记得修改且每一台机器不一样~
4.3.kafka内存启动
kafka节点默认需要的内存为1G,如果需要修改内存,可以修改kafka-server-start.sh的配置项。
vi /data/kafka_test/kafka/bin/kafka-server-start.sh
#找到KAFKA_HEAP_OPTS配置项,例如修改如下:export KAFKA_HEAP_OPTS=”-Xmx2G -Xms2G”
默认如下图:

4.4启动停止kafka命令
#启动kafka
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
#shell同时启动
#! /bin/bash
ssh root@hadoop4 kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
ssh root@hadoop5 kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
ssh root@hadoop6 kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
#停止kafka
kafka-server-stop.sh
#shell同时停止
#! /bin/bash
ssh root@hadoop4 kafka-server-stop.sh
ssh root@hadoop5 kafka-server-stop.sh
ssh root@hadoop6 kafka-server-stop.sh
5.创建测试topic
创建32分区、2备份
kafka-topics.sh --create --zookeeper hadoop4:2181 --topic TEST_JS --replication-factor 2 --partitions 32
常用命令:
1.展示topic
kafka-topics.sh –list –zookeeper hadoop4:2181
2.创建topic
kafka-topics.sh –create –zookeeper hadoop4:2181,hadoop5:2181,hadoop6:2181 –replication-factor 1 –partitions 1 –topic topic_name
3.查看描述topic
kafka-topics.sh –describe –zookeeper hadoop4:2181,hadoop5:2181,hadoop6:2181 –topic topic_name
4.生产者发送消息
kafka-console-producer.sh –broker-list hadoop5:9092 –topic topic_name
5.消费者消费消息
kafka-console-consumer.sh –bootstrap-server hadoop4:9092,hadoop5:9092,hadoop6:9092 –topic topic_name
6.删除topic
kafka-topics.sh –delete –topic topic_name –zookeeper hadoop4:2181,hadoop5:2181,hadoop6:2181
7.查看每分区consumer_offsets(可以连接到的消费主机)
kafka-topics.sh –describe –zookeeper hadoop4:2181,hadoop5:2181,hadoop6:2181 –topic __consumer_offsets