银河麒麟V10服务器系统快速利用RKE部署K8S
前言
因为后续服务器使用的操作系统是国产银河麒麟V10,那也需要预研一下。就各种踩坑
国产银河麒麟V10我初步看了下也是基于Centos8进行自己的魔改的
运行环境
服务器整体规划
| 名称 | IP | 组件 |
|---|---|---|
| k8s-188 | 192.168.100.188 | controlplane,etcd、rancher(网络原因可暂时忽略)、rke、kubectl |
| k8s-189 | 192.168.100.189 | controlplane,etcd |
| k8s-190 | 192.168.100.190 | worker,etcd,ingress |
软件环境
| 软件 | 版本 |
|---|---|
| docker | 19.03.15 |
| 操作系统 | Kylin Linux Advanced Server V10 (Lance) |
| 内核 | 4.19.90-52.15.v2207.ky10.x86_64 |
| 硬件配置 | 4GB,2个CPU,硬盘30GB |
初始化环境准备
所有机器执行
安装依赖包
yum install -y conntrack ntpdate ntp ipvsadm ipset iptables curl sysstat libseccomp wget vim net-tools git
#根据规划设置主机名
hostnamectl set-hostname <hostname> #分别设置为 k8s-188、k8s-189、k8s-190
hostname #确认是否配置生效
# 关闭防火墙,这里有个小坑哦~麒麟的系统是默认了iptables
systemctl stop firewalld && systemctl disable firewalld
yum -y install iptables-services && systemctl start iptables && systemctl enable iptables && iptables -F && service iptables save
#关闭selinux,
setenforce 0
#修改/etc/selinux/config文件,因为文件好几个SELINUX=disabled给注释了暂时手动修改/etc/selinux/config文件
vim /etc/selinux/config
#SELINUX=disabled
# setenforce 0 && sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
#关闭swap
swapoff -a && sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
#文件数设置
ulimit -SHn 65535
cat >> /etc/security/limits.conf <<EOF
* soft nofile 655360
* hard nofile 131072
* soft nproc 655350
* hard nproc 655350
* seft memlock unlimited
* hard memlock unlimitedd
EOF
#在master添加hosts
cat >> /etc/hosts << EOF
192.168.100.188 k8s-188
192.168.100.189 k8s-189
192.168.100.190 k8s-190
EOF
#将桥接的IPv4流量传递到iptables的链
cat > /etc/sysctl.d/k8s.conf << EOF
#开启网桥模式【重要】
net.bridge.bridge-nf-call-iptables=1
#开启网桥模式【重要】
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
net.ipv4.tcp_tw_recycle=0
# 禁止使用 swap 空间,只有当系统 OOM 时才允许使用它
vm.swappiness=0
# 不检查物理内存是否够用
vm.overcommit_memory=1
# 开启 OOM
vm.panic_on_oom=0
fs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=1048576
fs.file-max=52706963
fs.nr_open=52706963
#关闭ipv6【重要】
net.ipv6.conf.all.disable_ipv6=1
net.netfilter.nf_conntrack_max=2310720
EOF
# 加载网桥过滤模块
modprobe br_netfilter
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4
# 查看网桥过滤模块是否成功加载
lsmod | grep br_netfilter
# 重新刷新配置
sysctl -p /etc/sysctl.d/k8s.conf
# 保证在节点重启后能自动加载所需模块
cat >> /etc/rc.d/rc.local << EOF
bash /etc/sysconfig/modules/ipvs.modules
EOF
chmod +x /etc/rc.d/rc.local
#时间同步
yum install ntpdate -y
#ntpdate time.windows.com
ntpdate ntp1.aliyun.com
#或者配置crontab执行:
`crontab -e`
0 */1 * * * /usr/sbin/ntpdate ntp1.aliyun.com
echo "0 */1 * * * /usr/sbin/ntpdate ntp1.aliyun.com" >> /var/spool/cron/root
#关闭及禁用邮件服务
#systemctl stop postfix && systemctl disable postfix
# 设置ssh 这个非常重要,不然等下rke部署会出现 Failed to set up SSH tunneling for host 错误
sed -i 's/^AllowTcpForwarding no/AllowTcpForwarding yes/' /etc/ssh/sshd_config
systemctl restart sshd
设置 rsyslogd 和 systemd journald
mkdir /var/log/journal # 持久化保存日志的目录
mkdir /etc/systemd/journald.conf.d
cat > /etc/systemd/journald.conf.d/99-prophet.conf <<EOF
[Journal]
# 持久化保存到磁盘
Storage=persistent
# 压缩历史日志
Compress=yes
SyncIntervalSec=5m
RateLimitInterval=30s
RateLimitBurst=1000
# 最大占用空间 10G
SystemMaxUse=10G
# 单日志文件最大 200M
SystemMaxFileSize=200M
# 日志保存时间 2 周
MaxRetentionSec=2week
# 不将日志转发到 syslog
ForwardToSyslog=no
EOF
systemctl restart systemd-journald
安装Docker
因为麒麟v10基于Centos8的,系统内核版本是 4.19,所以就参考Centons8部署docker模式部署即可啦~虽然开始有点小恐惧(恐惧来源未知)
配置阿里云Centos8镜像源
之所以要配置 Centos8 的镜像源是因为在安装docker的时候需要额外的一些依赖,而这些依赖在麒麟官方的源里面是没有的
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-8.repo
配置阿里云 docker 镜像源
“`shell\
yum-config-manager –add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
sed -i ‘s+download.docker.com+mirrors.aliyun.com/docker-ce+’ /etc/yum.repos.d/docker-ce.repo
### **定义 yum 变量&修改 repo**
修改 centos 和 docker `repo`文件中的 `$releasever` 为 `centos_version` ,原因是在麒麟服务器操作系统V10中 `$releasever`被修改为了 10,而我们需要使用 centos 8的镜像源,如果你不替换,基本上仓库就无法找到对应文件了
```shell
echo "8" > /etc/yum/vars/centos_version
sed -i 's/$releasever/$centos_version/g' /etc/yum.repos.d/docker-ce.repo
sed -i 's/$releasever/$centos_version/g' /etc/yum.repos.d/CentOS-Base.repo
建立yum缓存
dnf makecache或者yum makecache
centos 8 后续的yum 其实就是dnf的一个软连接
查看docker-ce 版本
[root@k8s-189 ~]# yum list docker-ce --showduplicates | sort -r
docker-ce.x86_64 3:23.0.1-1.el8 docker-ce-stable
docker-ce.x86_64 3:23.0.0-1.el8 docker-ce-stable
docker-ce.x86_64 3:20.10.9-3.el8 docker-ce-stable
docker-ce.x86_64 3:20.10.8-3.el8 docker-ce-stable
docker-ce.x86_64 3:20.10.7-3.el8 docker-ce-stable
docker-ce.x86_64 3:20.10.6-3.el8 docker-ce-stable
docker-ce.x86_64 3:20.10.5-3.el8 docker-ce-stable
docker-ce.x86_64 3:20.10.4-3.el8 docker-ce-stable
docker-ce.x86_64 3:20.10.3-3.el8 docker-ce-stable
docker-ce.x86_64 3:20.10.2-3.el8 docker-ce-stable
docker-ce.x86_64 3:20.10.23-3.el8 docker-ce-stable
docker-ce.x86_64 3:20.10.22-3.el8 docker-ce-stable
docker-ce.x86_64 3:20.10.21-3.el8 docker-ce-stable
docker-ce.x86_64 3:20.10.20-3.el8 docker-ce-stable
docker-ce.x86_64 3:20.10.19-3.el8 docker-ce-stable
docker-ce.x86_64 3:20.10.18-3.el8 docker-ce-stable
docker-ce.x86_64 3:20.10.17-3.el8 docker-ce-stable
docker-ce.x86_64 3:20.10.16-3.el8 docker-ce-stable
docker-ce.x86_64 3:20.10.15-3.el8 docker-ce-stable
docker-ce.x86_64 3:20.10.14-3.el8 docker-ce-stable
docker-ce.x86_64 3:20.10.1-3.el8 docker-ce-stable
docker-ce.x86_64 3:20.10.13-3.el8 docker-ce-stable
docker-ce.x86_64 3:20.10.12-3.el8 docker-ce-stable
docker-ce.x86_64 3:20.10.11-3.el8 docker-ce-stable
docker-ce.x86_64 3:20.10.10-3.el8 docker-ce-stable
docker-ce.x86_64 3:20.10.0-3.el8 docker-ce-stable
docker-ce.x86_64 3:19.03.15-3.el8 docker-ce-stable
docker-ce.x86_64 3:19.03.15-3.el8 @docker-ce-stable
docker-ce.x86_64 3:19.03.14-3.el8 docker-ce-stable
docker-ce.x86_64 3:19.03.13-3.el8 docker-ce-stable
安装docker
这里要安装docker-ce 19.03 版本,因为我在使用最新版 20.10 启动容器时出现了未知的权限问题。至于为啥暂时在网络上我也未找到对应资料。
# 必须先卸载podman,因为containerd已经被占用了
yum remove podman
yum install docker-ce-19.03.15 docker-ce-cli-19.03.15 containerd.io -y
启动docker
systemctl start docker
# 查看当前版本号,是否启动成功
docker version
# 设置开机自启动
systemctl enable docker
设置docker-daemon.json
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": [
"https://registry.cn-hangzhou.aliyuncs.com",
"https://mirror.ccs.tencentyun.com",
"https://8i25ptuf.mirror.aliyuncs.com",
"https://hub-mirror.c.163.com",
"https://docker.mirrors.ustc.edu.cn",
"https://mirror.baidubce.com"
],
"exec-opts": ["native.cgroupdriver=systemd"],
"live-restore":true,
"log-driver":"json-file",
"log-opts": {"max-size":"200m", "max-file":"3"},
"max-concurrent-downloads": 10,
"storage-driver": "overlay2"
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker
注意,一定要保证该文件符合
json规范,否则 Docker 将不能启动。
阿里云加速的url为系统分配你们使用我的也没用…可抛弃执行
docker info,如果从结果中看到了如下内容,说明配置成功。
添加创建普通用户
为了安全起见,能不使用 root 账号操作就不使用,因此要添加专用的账号进行 docker 操作。
需要在每个节点重复该操作添加账号
创建 rancher 用户,添加到 docker 组
useradd rancher
usermod -aG docker rancher
# echo 模式在强校验的centos8不生效
#echo rancher | passwd --stdin rancher
passwd rancher
RKE所在主机上创建密钥
RKE所在主机k8s-188创建ssh-key,执行
#k8s-188 生成的密钥
ssh-keygen
#k8s-188 将所生成的密钥的公钥分发到各个节点
ssh-copy-id rancher@k8s-188
ssh-copy-id rancher@k8s-189
ssh-copy-id rancher@k8s-190
RKE工具下载
k8s-188服务器执行
具体最新版本可看github
curl -L "https://github.com/rancher/rke/releases/download/v1.3.19/rke_linux-amd64" -o /usr/local/bin/rke
chmod +x /usr/local/bin/rke
ln -s /usr/local/bin/rke /usr/bin/rke
rke -v
# rke version v1.3.19
初始化配置文件(编写配置文件)
nodes:
- address: 192.168.100.188
internal_address: 192.168.100.188
hostname_override: k8s-188
user: rancher
role: [controlplane,etcd]
docker_socket: /var/run/docker.sock
ssh_key_path: ~/.ssh/id_rsa
- address: 192.168.100.189
internal_address: 192.168.100.189
hostname_override: k8s-189
user: rancher
role: [controlplane,etcd]
docker_socket: /var/run/docker.sock
ssh_key_path: ~/.ssh/id_rsa
- address: 192.168.100.190
internal_address: 192.168.100.190
hostname_override: k8s-190
user: rancher
role: [worker,etcd]
docker_socket: /var/run/docker.sock
ssh_key_path: ~/.ssh/id_rsa
services:
kube-api:
extra_args:
watch-cache: true
default-watch-cache-size: 1500
# 事件保留时间,默认1小时
event-ttl: 1h0m0s
# 默认值400,设置0为不限制,一般来说,每25~30个Pod有15个并行
max-requests-inflight: 800
# 默认值200,设置0为不限制
max-mutating-requests-inflight: 400
# kubelet操作超时,默认5s
kubelet-timeout: 10s
# 为NodePort服务提供不同的端口范围
service_node_port_range: 30000-50000
kube-controller:
extra_args:
# 修改每个节点子网大小(cidr掩码长度),默认为24,可用IP为254个;23,可用IP为510个;22,可用IP为1022个;
node-cidr-mask-size: '24'
# eature-gates: "TaintBasedEvictions=false"
# 控制器定时与节点通信以检查通信是否正常,周期默认5s
node-monitor-period: '5s'
## 当节点通信失败后,再等一段时间kubernetes判定节点为notready状态。
## 这个时间段必须是kubelet的nodeStatusUpdateFrequency(默认10s)的整数倍,
## 其中N表示允许kubelet同步节点状态的重试次数,默认40s。
node-monitor-grace-period: '20s'
## 再持续通信失败一段时间后,kubernetes判定节点为unhealthy状态,默认1m0s。
node-startup-grace-period: '30s'
## 再持续失联一段时间,kubernetes开始迁移失联节点的Pod,默认5m0s。
pod-eviction-timeout: '1m'
# 默认30. 与apiserver通信并发数。
kube-api-burst: 60
# 默认20. 与kubernetes apiserver交谈时使用的QPS,QPS = 并发量 / 平均响应时间
kube-api-qps: 40
etcd:
backup_config:
# 设置true启用ETCD自动备份,设置false禁用
enabled: true
# 快照创建间隔时间,单位小时
interval_hours: 2
# 快照的存活时间(快照的存活时间,单位是小时)
retention: 360
# 修改空间配额为$((6*1024*1024*1024)),默认2G,最大8G
extra_args:
quota-backend-bytes: '6442450944'
auto-compaction-retention: 240
kubelet:
extra_args:
# 传递给网络插件的MTU值,以覆盖默认值,设置为0(零)则使用默认的1460
network-plugin-mtu: '1500'
# 修改节点最大Pod数量
max-pods: "250"
# Kubelet进程可以打开的文件数(默认1000000),根据节点配置情况调整
max-open-files: '2000000'
# 与apiserver会话时的并发数,默认是10
kube-api-burst: '30'
# 与apiserver会话时的 QPS,默认是5,QPS = 并发量/平均响应时间
kube-api-qps: '15'
# kubelet默认一次拉取一个镜像,设置为false可以同时拉取多个镜像,
# 前提是存储驱动要为overlay2,对应的Dokcer也需要增加下载并发数,参考[docker配置](https://www.rancher.cn/docs/rancher/v2.x/cn/install-prepare/best-practices/docker/)
serialize-image-pulls: 'false'
# 拉取镜像的最大并发数,registry-burst不能超过registry-qps。
# 仅当registry-qps大于0(零)时生效,(默认10)。如果registry-qps为0则不限制(默认5)。
registry-burst: '10'
registry-qps: '0'
cgroups-per-qos: 'true'
cgroup-driver: 'cgroupfs'
# 节点资源预留
enforce-node-allocatable: 'pods'
system-reserved: 'cpu=0.25,memory=200Mi'
kube-reserved: 'cpu=0.25,memory=1500Mi'
kubeproxy:
extra_args:
# 默认使用iptables进行数据转发,如果要启用ipvs,则此处设置为`ipvs`
ipvs-scheduler: rr
proxy-mode: ipvs
# 与kubernetes apiserver通信并发数,默认10;
kube-api-burst: 20
# 与kubernetes apiserver通信时使用QPS,默认值5,QPS = 并发量 / 平均响应时间
kube-api-qps: 10
# 设置calico网络插件
network:
plugin: calico
ingress:
extra_envs:
- name: TZ
value: Asia/Shanghai
kubernetes_version: v1.20.15-rancher2-2
请参考RKE 版本说明,获取您当前使用的 RKE 支持的 Kubernetes 版本号。
也可以输入:
rke config --list-version --all,快速获取支持的版本号
部署集群
执行命令
master01服务器执行
rke up --config cluster.yml
# rke up --config cluster.yml
.....
INFO[0414] [addons] Setting up user addons
INFO[0414] [addons] no user addons defined
INFO[0414] Finished building Kubernetes cluster successfully
过程中遇到的坑
[root@k8s-188 rke]# rke up --config cluster.yaml
INFO[0000] Running RKE version: v1.3.19
INFO[0000] Initiating Kubernetes cluster
INFO[0000] [certificates] GenerateServingCertificate is disabled, checking if there are unused kubelet certificates
INFO[0000] [certificates] Generating admin certificates and kubeconfig
INFO[0000] Successfully Deployed state file at [./cluster-v10.rkestate]
INFO[0000] Building Kubernetes cluster
INFO[0000] [dialer] Setup tunnel for host [192.168.100.188]
INFO[0000] [dialer] Setup tunnel for host [192.168.100.189]
INFO[0000] [dialer] Setup tunnel for host [192.168.100.190]
WARN[0000] Failed to set up SSH tunneling for host [192.168.100.190]: Can't retrieve Docker Info: error during connect: Get "http://%2Fvar%2Frun%2Fdocker.sock/v1.24/info": Unable to access the service on /var/run/docker.sock. The service might be still starting up. Error: ssh: rejected: connect failed (open failed)
WARN[0000] Failed to set up SSH tunneling for host [192.168.100.189]: Can't retrieve Docker Info: error during connect: Get "http://%2Fvar%2Frun%2Fdocker.sock/v1.24/info": Unable to access the service on /var/run/docker.sock. The service might be still starting up. Error: ssh: rejected: connect failed (open failed)
WARN[0000] Failed to set up SSH tunneling for host [192.168.100.188]: Can't retrieve Docker Info: error during connect: Get "http://%2Fvar%2Frun%2Fdocker.sock/v1.24/info": Unable to access the service on /var/run/docker.sock. The service might be still starting up. Error: ssh: rejected: connect failed (open failed)
通过查找官网issues :https://github.com/rancher/rke/issues/1417 反馈是
/etc/ssh/sshd_config文件AllowTcpForwarding参数必须是yes
如果报错则进一步排查。可以往下拉错误集那有没有和我遇到的错误一致
执行成功后当前目录下将会多出以下文件
root@k8s-188 rke]# ls -l
total 140
-rw------- 1 root root 127687 Feb 27 14:39 cluster.rkestate
-rw-r--r-- 1 root root 1425 Feb 27 14:33 cluster.yml
-rw------- 1 root root 5499 Feb 27 14:35 kube_config_cluster.yml
cluster.yml:RKE 集群的配置文件。-
kube_config_cluster.yml:该集群的Kubeconfig 文件包含了获取该集群所有权限的认证凭据。 -
cluster.rkestate:Kubernetes 集群状态文件,包含了获取该集群所有权限的认证凭据,使用 RKE v0.2.0 时才会创建这个文件。这3份文件很重要,一定要保存好!!
使用kubectl命令查看集群
下载kubectl命令工具
kubectl版本需要与k8s版本一致
curl -L "https://storage.googleapis.com/kubernetes-release/release/v1.20.15/bin/linux/amd64/kubectl" -o /usr/local/bin/kubectl
chmod +x /usr/local/bin/kubectl
ln -s /usr/local/bin/kubectl /usr/bin/kubectl
kubectl version --client
配置连接文件
mkdir ~/.kube
cd /data/rancher
cp kube_config_cluster.yml /root/.kube/
mv /root/.kube/kube_config_cluster.yml /root/.kube/config
查看集群状态
[root@k8s-188 ~]# kubectl get nodes,cs -o wide
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
node/k8s-188 Ready controlplane,etcd 8h v1.20.15 192.168.100.188 <none> Kylin Linux Advanced Server V10 (Lance) 4.19.90-52.15.v2207.ky10.x86_64 docker://19.3.15
node/k8s-189 Ready controlplane,etcd 8h v1.20.15 192.168.100.189 <none> Kylin Linux Advanced Server V10 (Lance) 4.19.90-52.15.v2207.ky10.x86_64 docker://19.3.15
node/k8s-190 Ready etcd,worker 8h v1.20.15 192.168.100.190 <none> Kylin Linux Advanced Server V10 (Lance) 4.19.90-52.15.v2207.ky10.x86_64 docker://19.3.15
NAME STATUS MESSAGE ERROR
componentstatus/controller-manager Healthy ok
componentstatus/scheduler Healthy ok
componentstatus/etcd-2 Healthy {"health":"true"}
componentstatus/etcd-1 Healthy {"health":"true"}
componentstatus/etcd-0 Healthy {"health":"true"}
到此,银河麒麟V10服务器系统快速利用RKE部署K8S完毕,后续就是一些验证的工作。
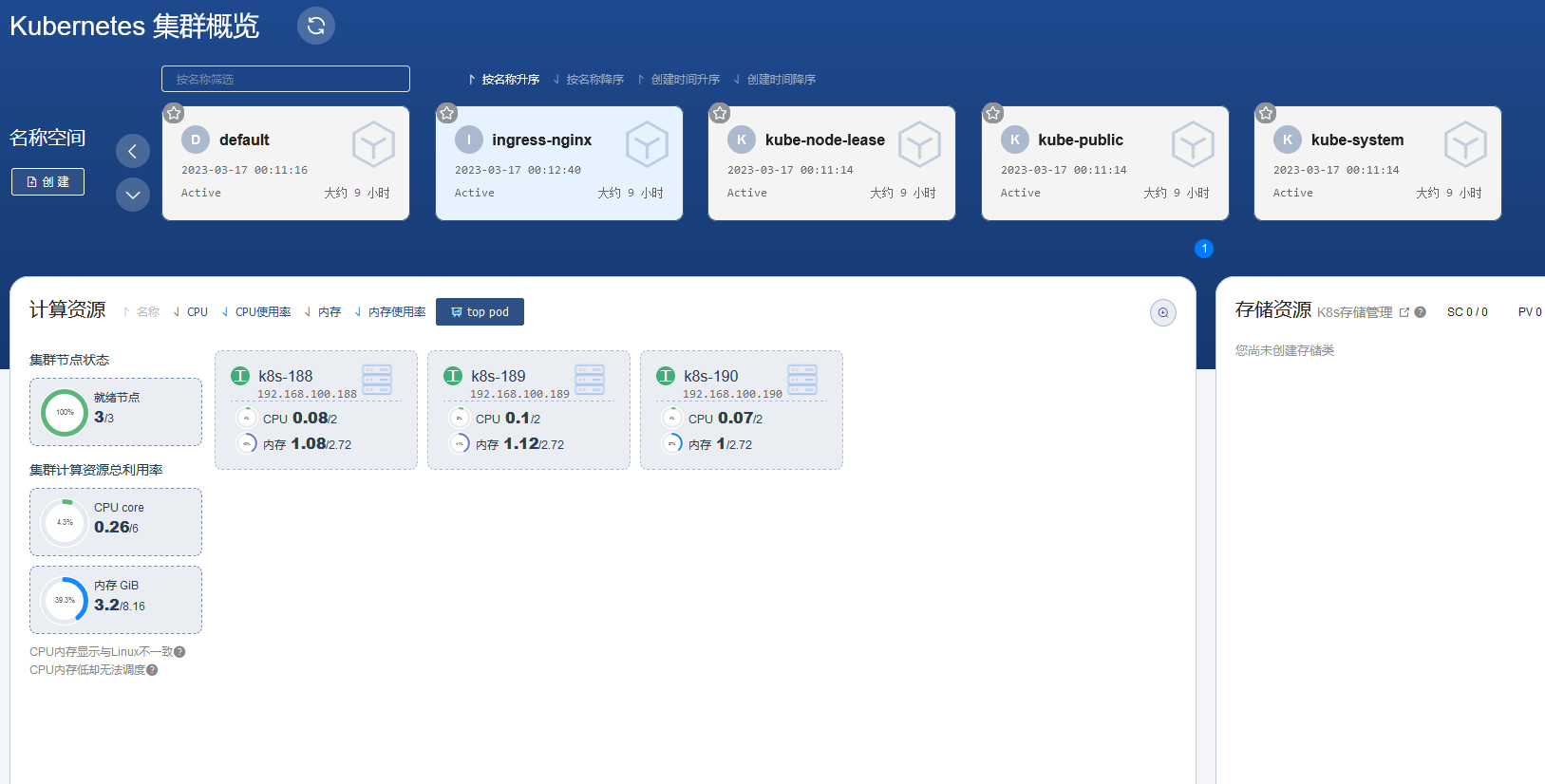
存在一些问题
1.暂时压测验证网络或者etcd的性能不太行~